
Paper Reading: Robot learning 1
I want to stand with them.
RL-BASED DRONE PAPER READING
Learning-based motor failure-tolerant control#
Learning-based attitude control under UAV motor anomalies
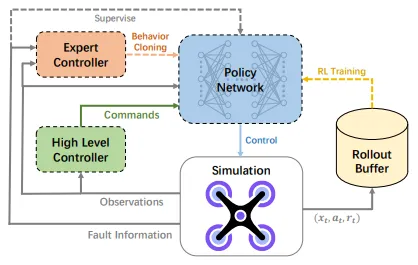 An RL-based control optimization method. It proposes a learning-based PFTC approach, and (to the best of my knowledge) is among the first to apply learning-based methods to real quadrotor motor-failure validation. It achieves performance comparable to AFTC methods that rely on prior fault information. For fault-tolerant control, it introduces a Selector-Controller network architecture that combines the strengths of existing PFTC and AFTC approaches. The policy network is updated by combining RL, behavior cloning (BC), and supervised learning with fault information. Overall it is a reinforcement-learning policy network + PPO as the policy, forming a learning-based passive fault-tolerant control (PFTC) method to handle single-rotor failure. As a control-type paper, the controller can be split into a high-level controller and a low-level controller: the high-level controller can largely stay unchanged using mature solutions, while the low-level controller can adopt a learning-based policy network.
An RL-based control optimization method. It proposes a learning-based PFTC approach, and (to the best of my knowledge) is among the first to apply learning-based methods to real quadrotor motor-failure validation. It achieves performance comparable to AFTC methods that rely on prior fault information. For fault-tolerant control, it introduces a Selector-Controller network architecture that combines the strengths of existing PFTC and AFTC approaches. The policy network is updated by combining RL, behavior cloning (BC), and supervised learning with fault information. Overall it is a reinforcement-learning policy network + PPO as the policy, forming a learning-based passive fault-tolerant control (PFTC) method to handle single-rotor failure. As a control-type paper, the controller can be split into a high-level controller and a low-level controller: the high-level controller can largely stay unchanged using mature solutions, while the low-level controller can adopt a learning-based policy network.
TACO#
A goal- and command-oriented RL framework (TACO) for diverse maneuvers with online parameter tuning
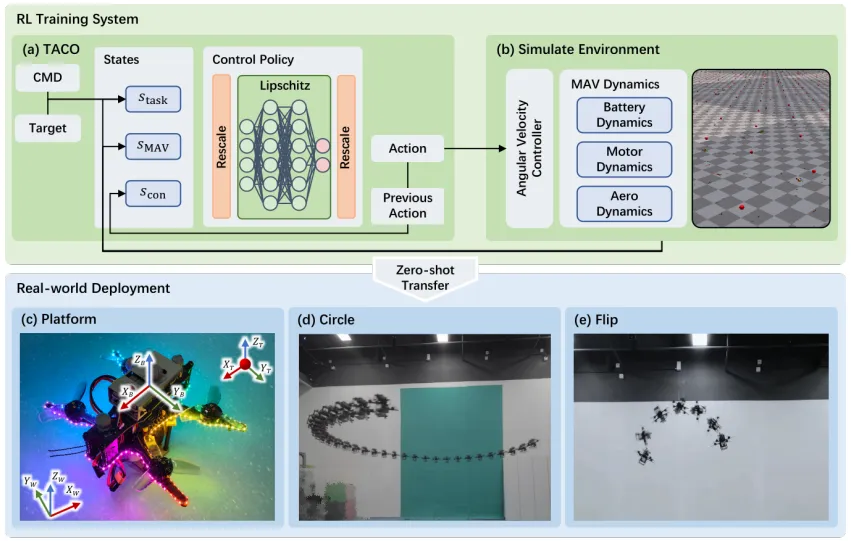 No need to predefine maneuver trajectories, and supports online adjustment of flight parameters. It learns different aerobatic maneuvers through a unified state-design formulation. It improves temporal/spatial smoothness, independence, and symmetry of the policy, without requiring complex dynamics models or reward functions, and bridges the sim-to-real gap in a “zero-shot” manner. It uses a spectral-normalization method combined with input/output rescaling to mitigate the sim-to-real gap.
No need to predefine maneuver trajectories, and supports online adjustment of flight parameters. It learns different aerobatic maneuvers through a unified state-design formulation. It improves temporal/spatial smoothness, independence, and symmetry of the policy, without requiring complex dynamics models or reward functions, and bridges the sim-to-real gap in a “zero-shot” manner. It uses a spectral-normalization method combined with input/output rescaling to mitigate the sim-to-real gap.
End-to-end Learning Approach#
Radar-data + DRL navigation and obstacle avoidance in dynamic environments
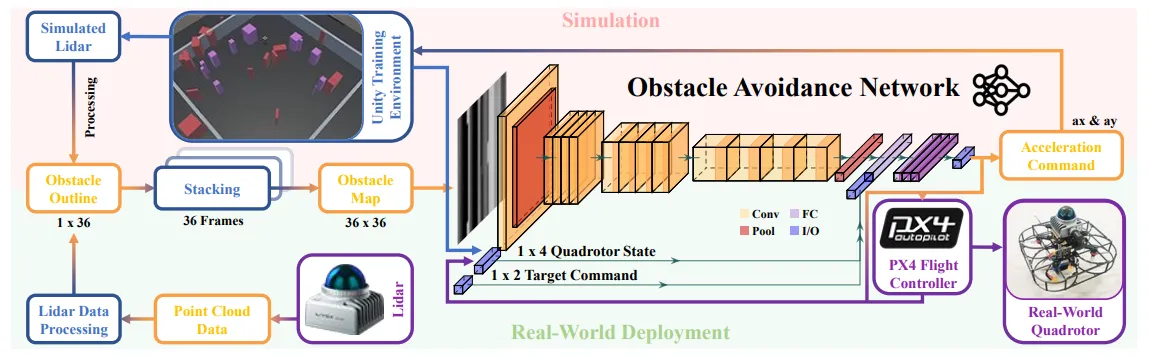 It compresses 3D point clouds into a 2D obstacle map that includes contours and motion features of both static and dynamic obstacles. An end-to-end deep neural network extracts kinematics information of dynamic/static obstacles from the obstacle map, and finally outputs acceleration commands to the quadrotor. The pipeline is: DRL-based navigation in highly dynamic environments + a LiDAR data encoder + an end-to-end deep neural network.
It compresses 3D point clouds into a 2D obstacle map that includes contours and motion features of both static and dynamic obstacles. An end-to-end deep neural network extracts kinematics information of dynamic/static obstacles from the obstacle map, and finally outputs acceleration commands to the quadrotor. The pipeline is: DRL-based navigation in highly dynamic environments + a LiDAR data encoder + an end-to-end deep neural network.
LiDAR-based Quadrotor#
Integrated Planning and Control (IPC) module enabling assisted obstacle avoidance for UAVs
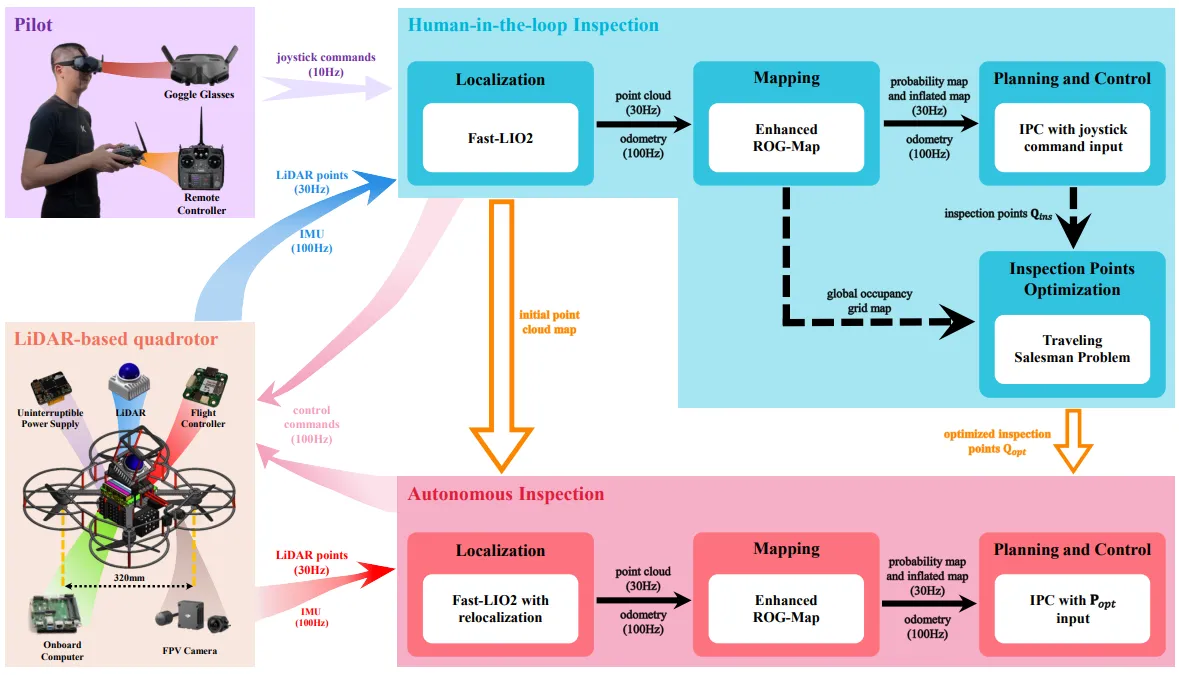 This work adopts an Integrated Planning and Control (IPC) module to enable assisted obstacle avoidance for UAVs, and names the adapted version APAS-IPC (an IPC-based Advanced Pilot Assistance System). The core idea is to tightly integrate planning and control into a linear Model Predictive Control (MPC) framework, generating optimal trajectories and corresponding control commands at 100 Hz. The key contribution is the APAS-IPC architecture.
This work adopts an Integrated Planning and Control (IPC) module to enable assisted obstacle avoidance for UAVs, and names the adapted version APAS-IPC (an IPC-based Advanced Pilot Assistance System). The core idea is to tightly integrate planning and control into a linear Model Predictive Control (MPC) framework, generating optimal trajectories and corresponding control commands at 100 Hz. The key contribution is the APAS-IPC architecture.
ROG-Map#
ROG-Map
Integration of LiDAR and occupancy grid maps (a uniform-grid occupancy map that maintains a local map moving with the robot, enabling efficient map operations while reducing memory cost for large-scale autonomous flight). It proposes a novel incremental update scheme that ensures computational complexity in all cases. On public datasets, it reduces the number of traversed grid cells by 70%-97%, significantly accelerating obstacle inflation.
STAF-Navi#
A DRL-based UAV navigation framework integrating internal memory and enhanced perception
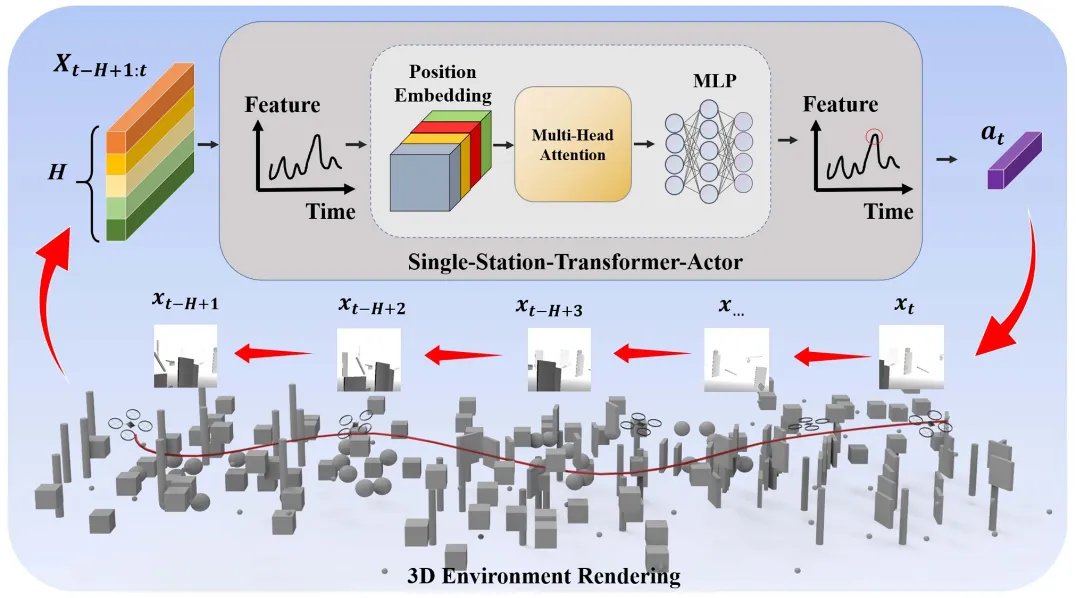 The Single-Station-Transformer-Actor (SSTA) model combines positional encoding with Transformer-based attention to fuse time-varying depth-image inputs and low-dimensional state information. Both the SSTA-based actor and the GRU-based critic process historical data, enabling the agent to integrate contextual information from past observations and actions. This ultimately allows the UAV to execute extended tasks requiring multi-step planning and sustained feedback.
The Single-Station-Transformer-Actor (SSTA) model combines positional encoding with Transformer-based attention to fuse time-varying depth-image inputs and low-dimensional state information. Both the SSTA-based actor and the GRU-based critic process historical data, enabling the agent to integrate contextual information from past observations and actions. This ultimately allows the UAV to execute extended tasks requiring multi-step planning and sustained feedback.
Flight in Clutter#
A flight-control framework for unknown cluttered environments
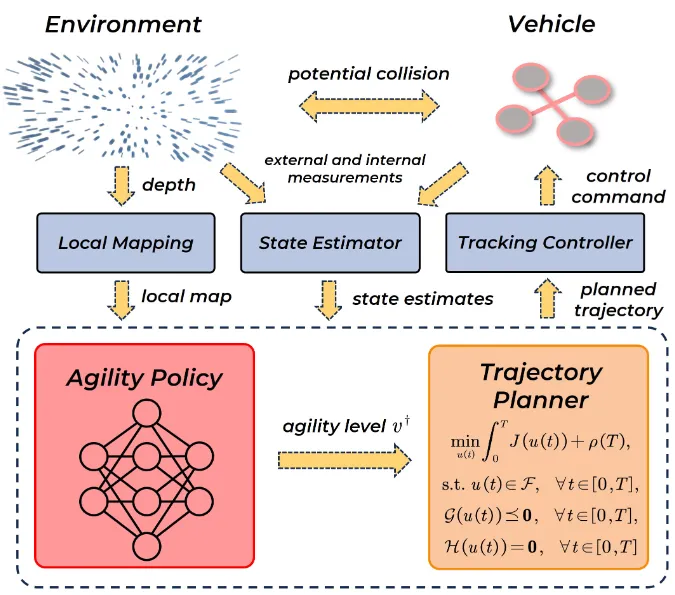 For aircraft flying in unknown cluttered environments, it proposes a hierarchical learning-planning framework that combines online reinforcement learning with model-based trajectory generation, allowing the vehicle to dynamically adjust speed constraints. A key contribution is a two-stage reward design that addresses sparsity and randomness in early-termination penalties. Simulation and real-world tests show better efficiency and safety than constant-speed baselines and EVA-planner, with strong perception capability.
For aircraft flying in unknown cluttered environments, it proposes a hierarchical learning-planning framework that combines online reinforcement learning with model-based trajectory generation, allowing the vehicle to dynamically adjust speed constraints. A key contribution is a two-stage reward design that addresses sparsity and randomness in early-termination penalties. Simulation and real-world tests show better efficiency and safety than constant-speed baselines and EVA-planner, with strong perception capability.
Drone Swarm#
Vision-based drone swarm with limited field of view
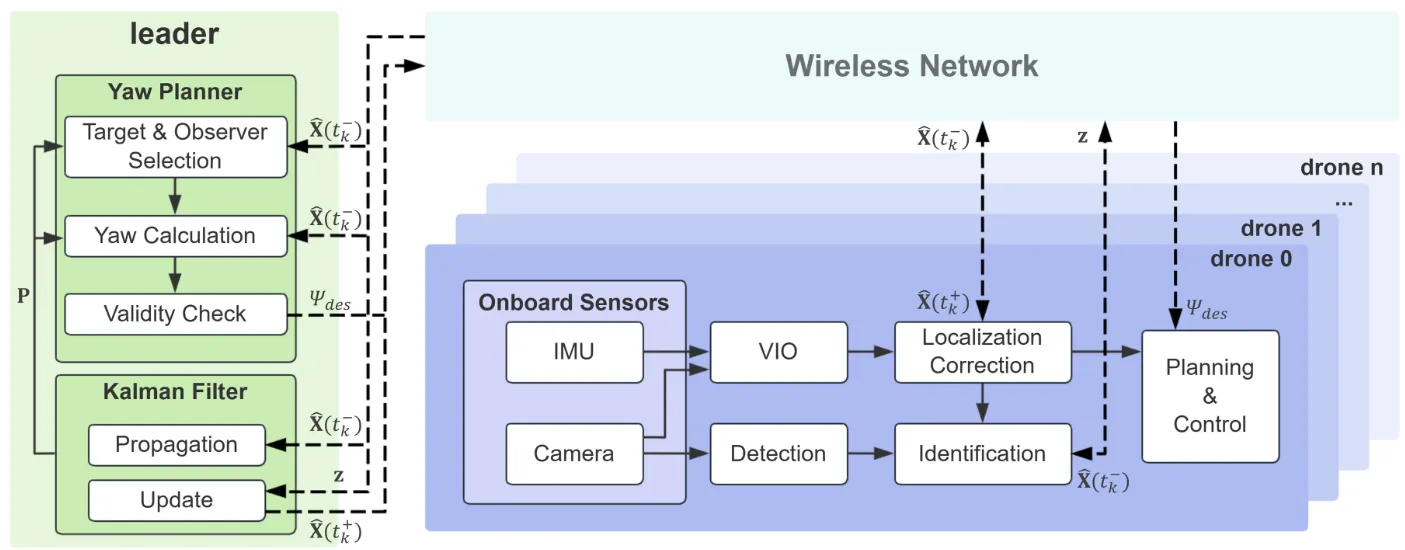 For vision-based drone swarms with limited field of view, it proposes an active localization-correction system that balances environment observation and mutual observation via yaw planning. The key contribution is quantifying localization uncertainty with Kalman filtering and assigning mutual-observation tasks; real-world tests reduce localization drift by up to 65% and maintain stable formation without GPS.
For vision-based drone swarms with limited field of view, it proposes an active localization-correction system that balances environment observation and mutual observation via yaw planning. The key contribution is quantifying localization uncertainty with Kalman filtering and assigning mutual-observation tasks; real-world tests reduce localization drift by up to 65% and maintain stable formation without GPS.
STD-Trees#
Trajectory optimization
To address slow convergence of sampling-based planning for multirotor dynamics, it proposes spatiotemporal deformable trees that optimize the spatial state and time duration of trajectory trees via deformation units. The key contribution is four deformation modes. Spatiotemporal deformation (vs spatial-only deformation) significantly accelerates convergence and improves trajectory quality, and is compatible with various RRT-family planners.
Radar Cross-Modal Diffusion Model#
Cross-modal diffusion model
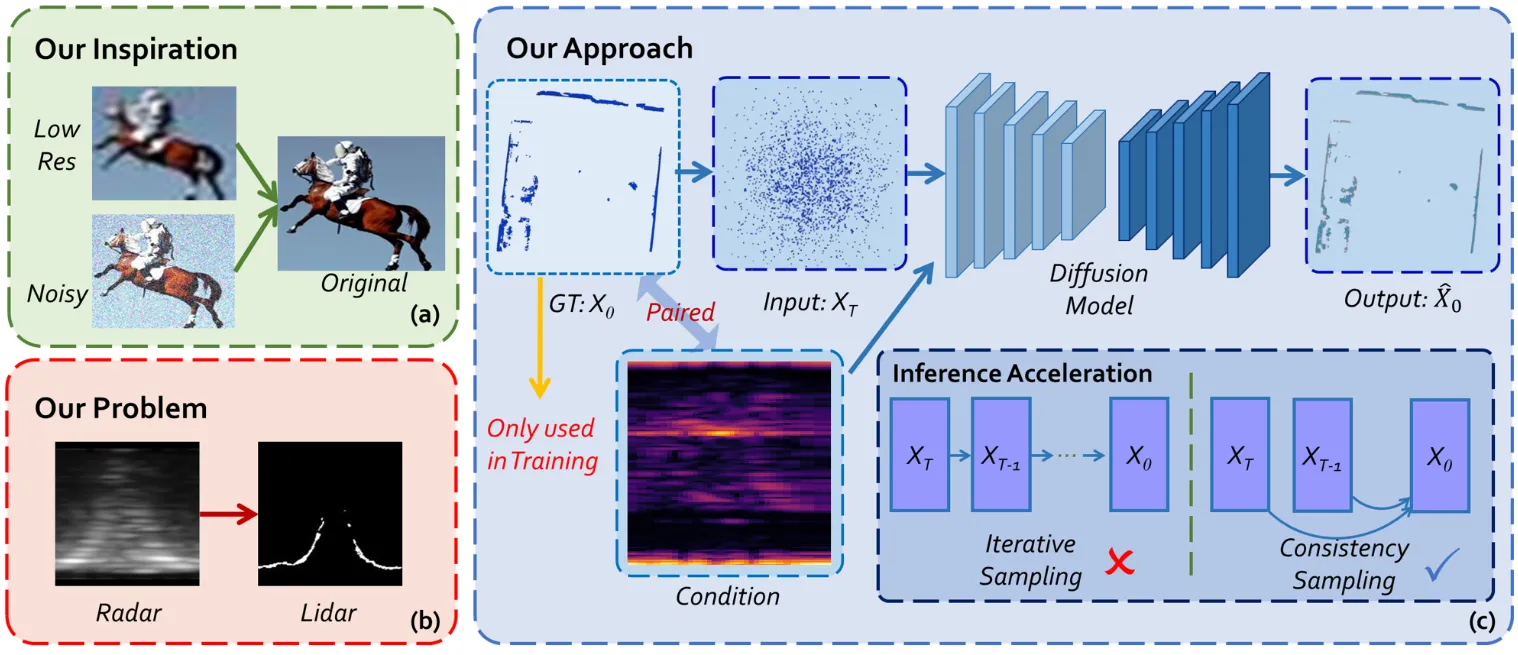 To address the sparsity and noise of mmWave radar point clouds, it proposes a cross-modal diffusion model that uses LiDAR supervision to generate dense radar point clouds, and combines a consistency model for one-step fast inference. The key contribution is applying diffusion models to UAV radar perception for the first time; it can run in real time on embedded platforms, and point-cloud quality and generalization outperform existing methods.
To address the sparsity and noise of mmWave radar point clouds, it proposes a cross-modal diffusion model that uses LiDAR supervision to generate dense radar point clouds, and combines a consistency model for one-step fast inference. The key contribution is applying diffusion models to UAV radar perception for the first time; it can run in real time on embedded platforms, and point-cloud quality and generalization outperform existing methods.