End-to-End RL Methods for UAVs
An overview from a broader research perspective
Preface#
Traditional Approaches to Autonomous Navigation and Intelligent Flight for UAVs#
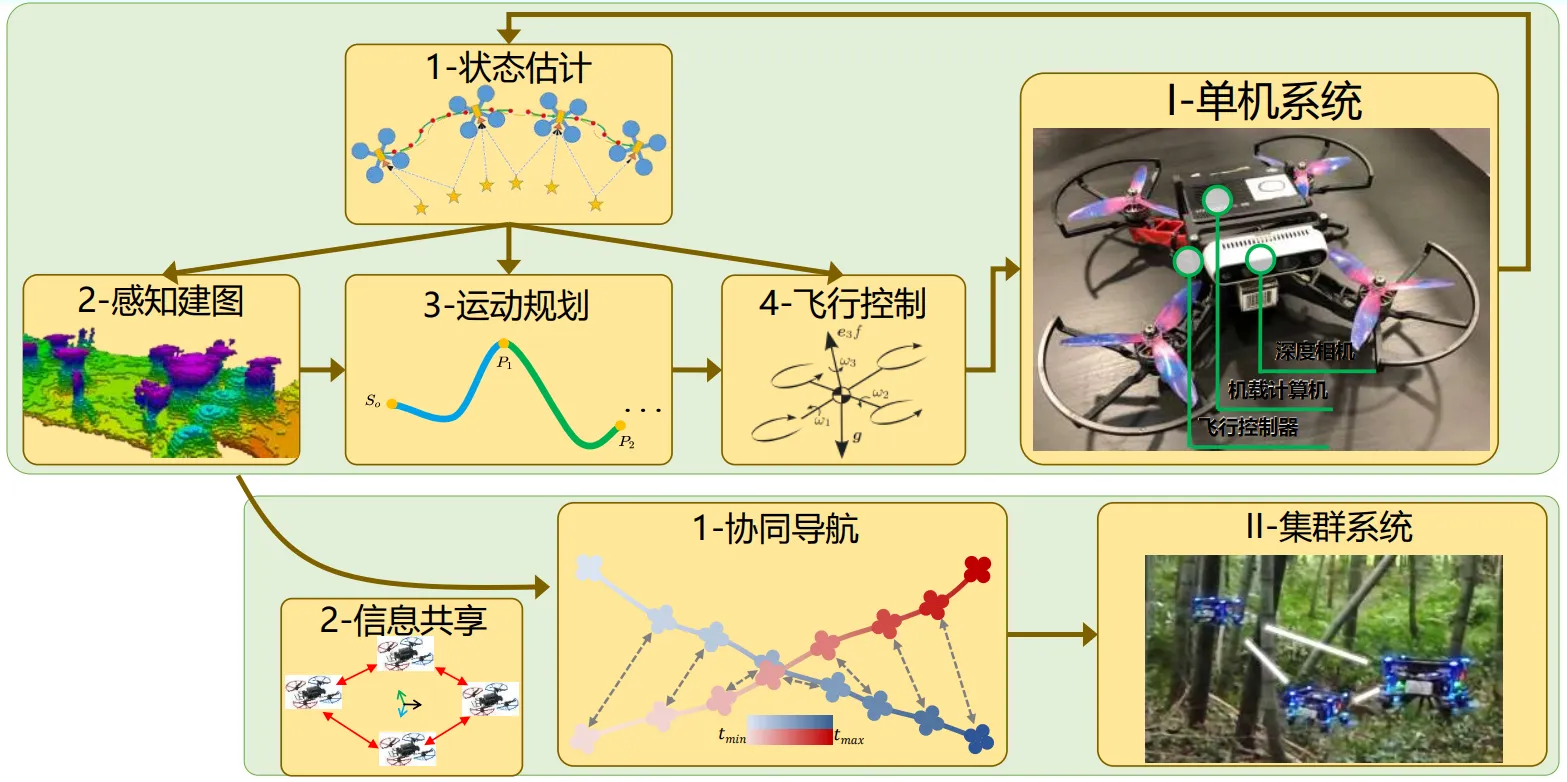
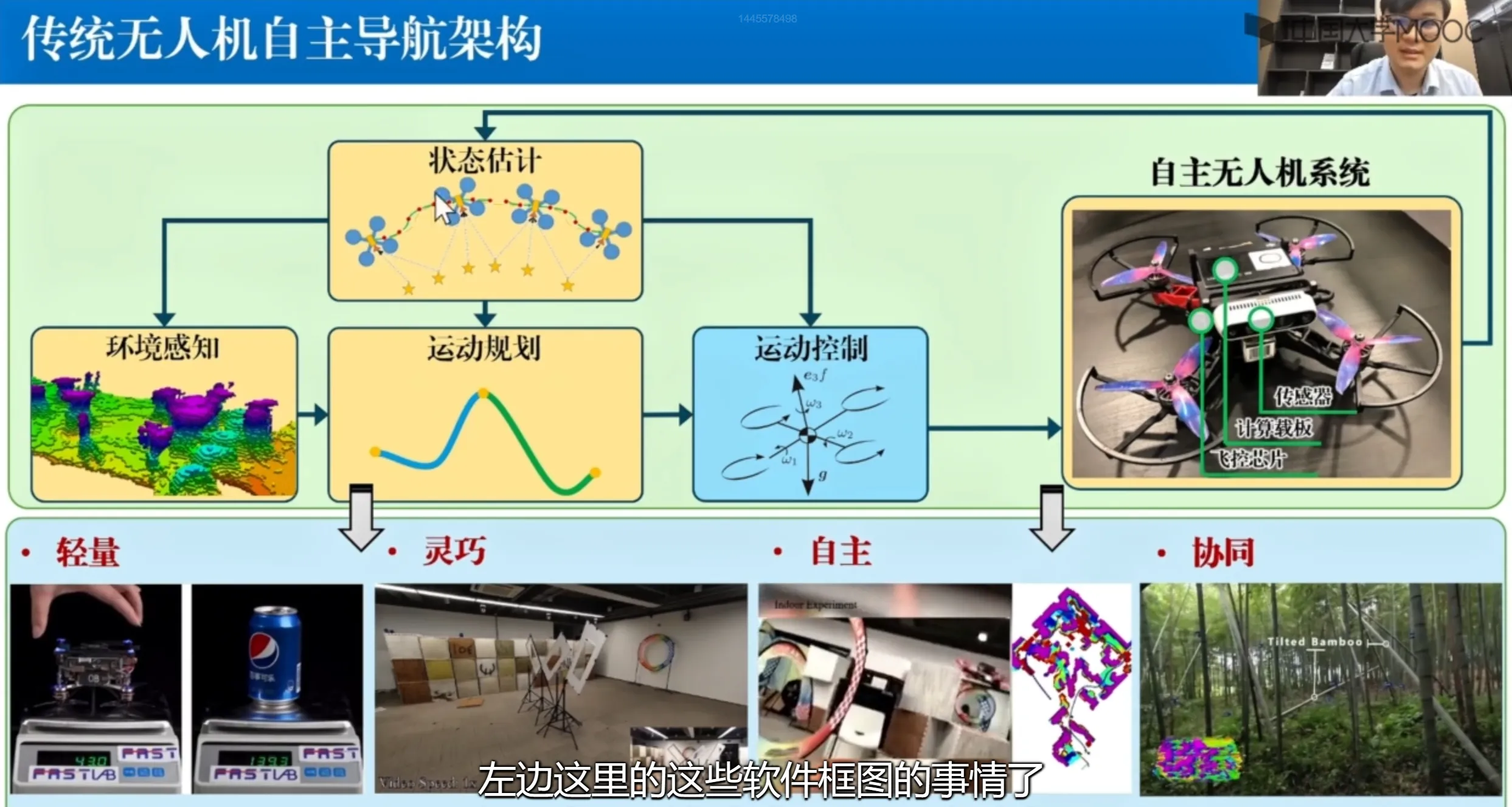
Autonomous navigation is a key cornerstone of UAV autonomy and a core technology that needs sustained effort. A typical traditional UAV autonomous navigation framework is shown below.
-
State estimation: The UAV infers its current state from images or other sensor information in the environment. This state includes higher-order motion states such as position, attitude, velocity, and angular velocity.
-
Environmental perception: Based on the estimated state, and combined with sensor data collected from the environment, the system reconstructs the environment in 3D. This lets the UAV know which areas are traversable and which are points of interest for the current task, resulting in a high-precision 3D situational map.
-
Motion planning: Motion planning is performed based on the constructed map and the inferred self-state. The plan must satisfy two requirements: safety (the UAV must not collide) and feasibility (the planned path must be physically meaningful).
-
Motion control: Keeps the UAV in a stable flight state. The velocity should track the desired velocity, and the attitude should be as stable as possible. After onboard computing finishes, commands are sent to the motors; specific rotor-speed commands are issued by the low-level flight controller chip.
-
Something else: These are modular components and are relatively independent of each other. The downside is also clear: it is difficult to jointly optimize across modules.
Differences Between End-to-End RL and Traditional Approaches#
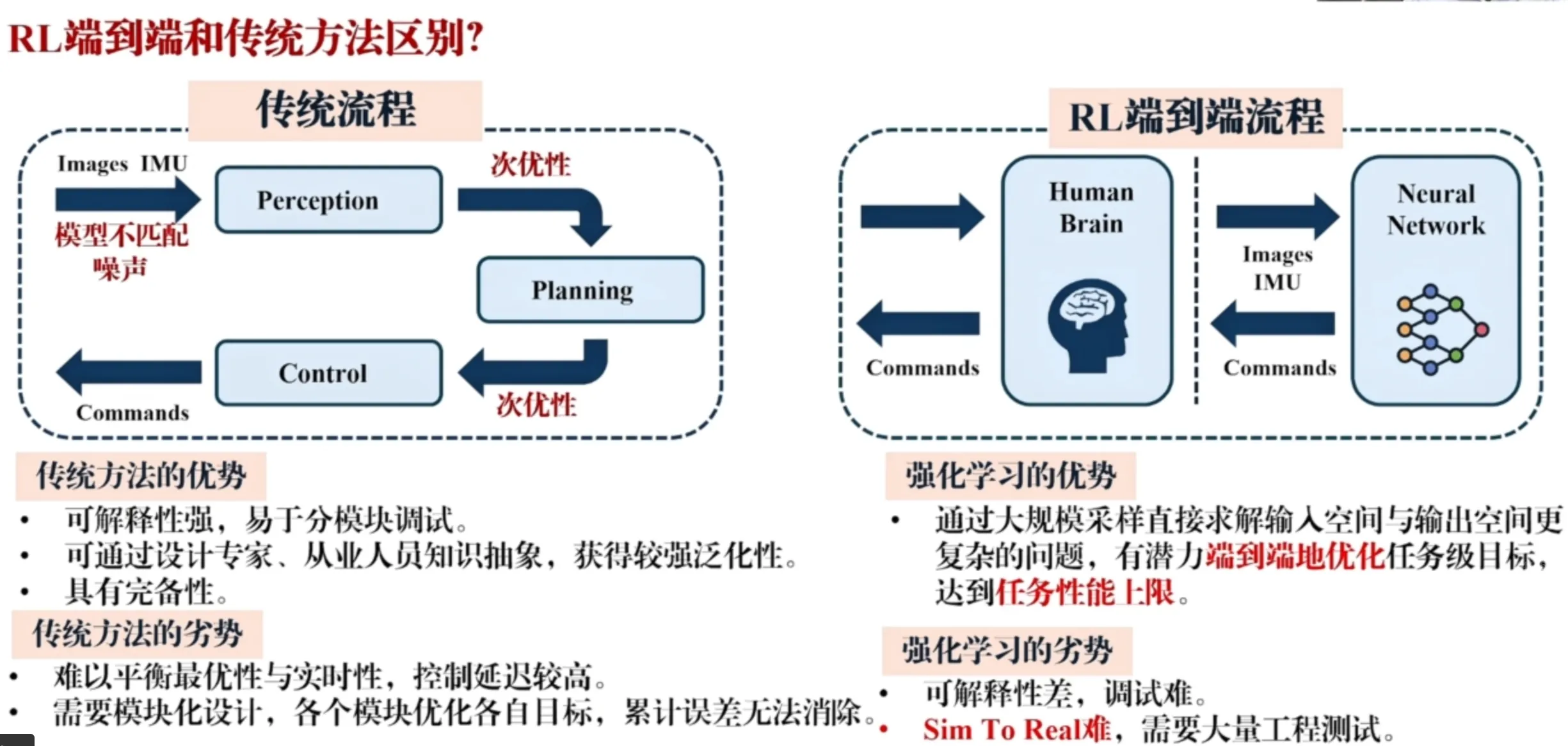
Reinforcement learning does not necessarily follow the sequence of: perception, build a map, plan trajectories on the map, then control along the planned trajectory. In practice, the whole process is a closed loop and end-to-end: sensors collect data at one end, and control commands are produced at the other end.
Essentially, this is an optimization of navigation at the system level. In a complex system made of traditional modular algorithms, even if each module reaches a local optimum, connecting them together does not mean the overall system reaches a global optimum. This is because gradients cannot flow between modules; they are disconnected.
End-to-end RL directly optimizes the entire model: one model solves the problem end-to-end, with a higher theoretical upper bound. RL networks can also be lighter-weight, using massive offline compute and training time to obtain efficient online inference. (Traditional methods often require strong online optimization and specialized mathematical solvers.) As a result, RL can achieve higher computational efficiency and reduce onboard-chip power consumption and cost requirements.
Traditional modular design can also accumulate errors. For example, vision sensors inevitably have noise and localization error; errors then accumulate during mapping and planning, degrading the overall system.
Advantages of traditional methods: Each module is carefully designed, transparent, highly interpretable, and easy to debug module-by-module (you can pinpoint which module causes an issue).
Disadvantages of RL methods: A black box. The whole system is one model; it may all work, or all fail. Debugging and development are difficult. Sim-to-real and real-to-sim require extensive engineering tests and practical deployment tricks.
Combining Traditional Methods and Reinforcement Learning (More Complete, Better Generalization)#
One idea is to replace part of the reinforcement learning network with a trajectory planner (better than being a complete black box).
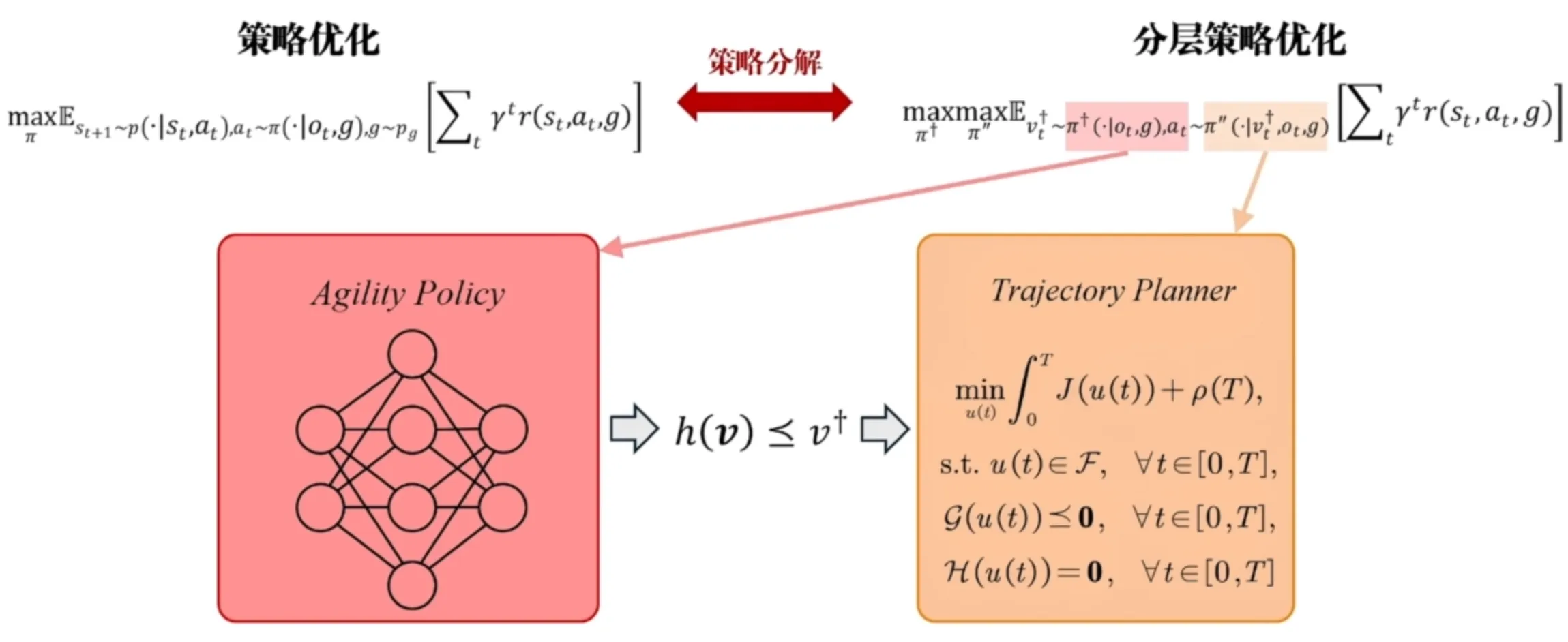
With a fully RL-based approach, changing the objective function may require retraining the RL network. But after introducing trajectory optimization, we can adjust the system simply by changing the objective function of the trajectory optimization.
An adaptive navigation framework based on reinforcement learning: RL outputs parameters required by trajectory optimization, specifically the maximum speed (a speed upper bound). Using RL as an automatic speed regulator for UAV flight (when obstacles are dense and visual blind spots exist, the UAV can slightly reduce speed to ensure safety).

Applications of Reinforcement Learning in UAV Pursuit-Evasion Games#
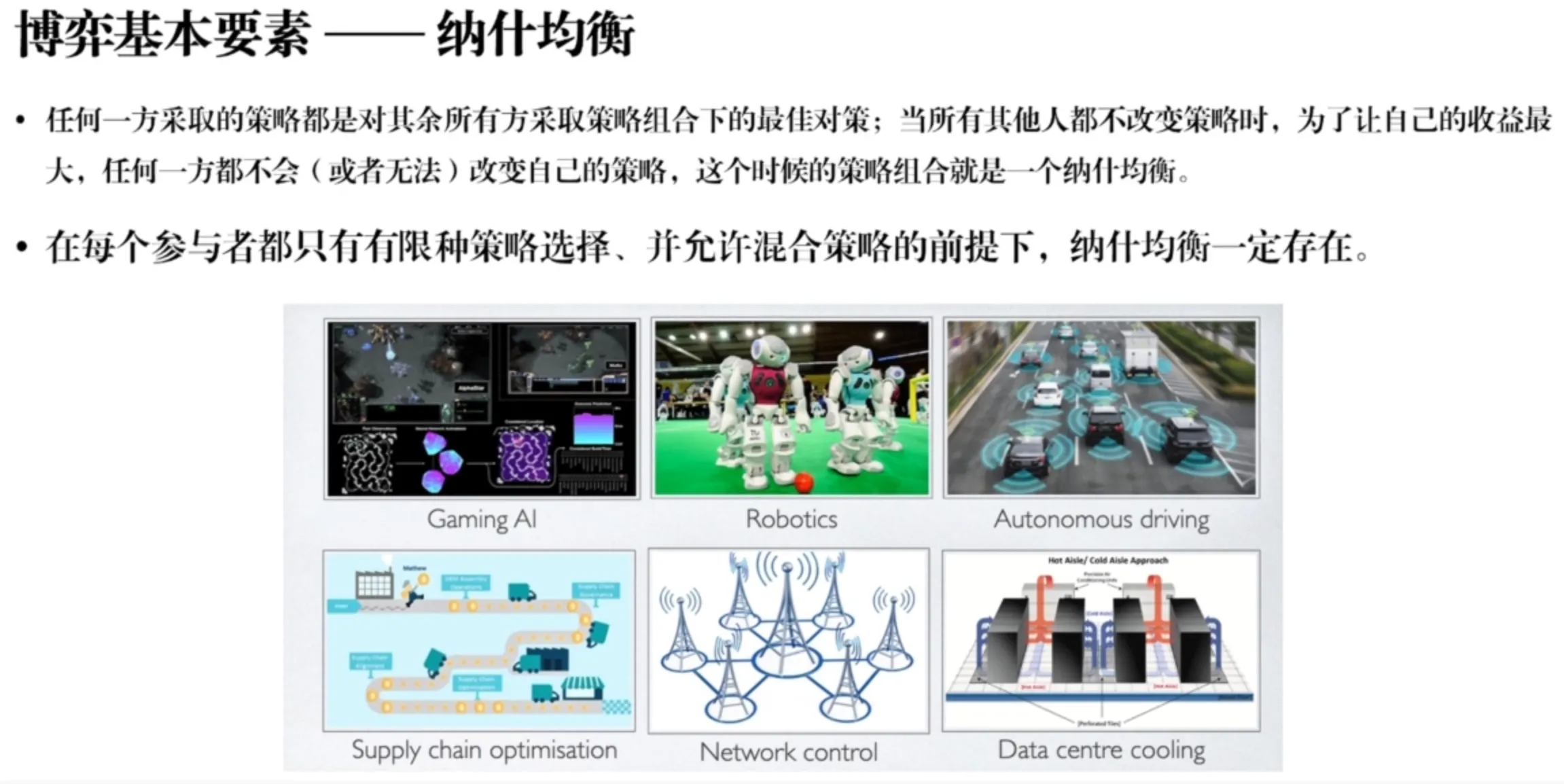
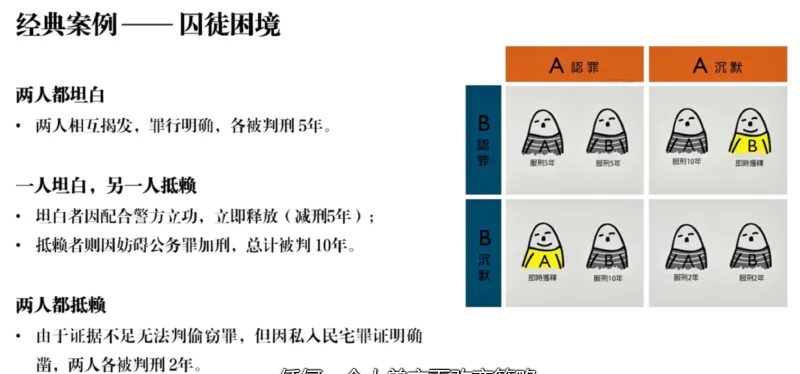
Basic elements and concepts of games.
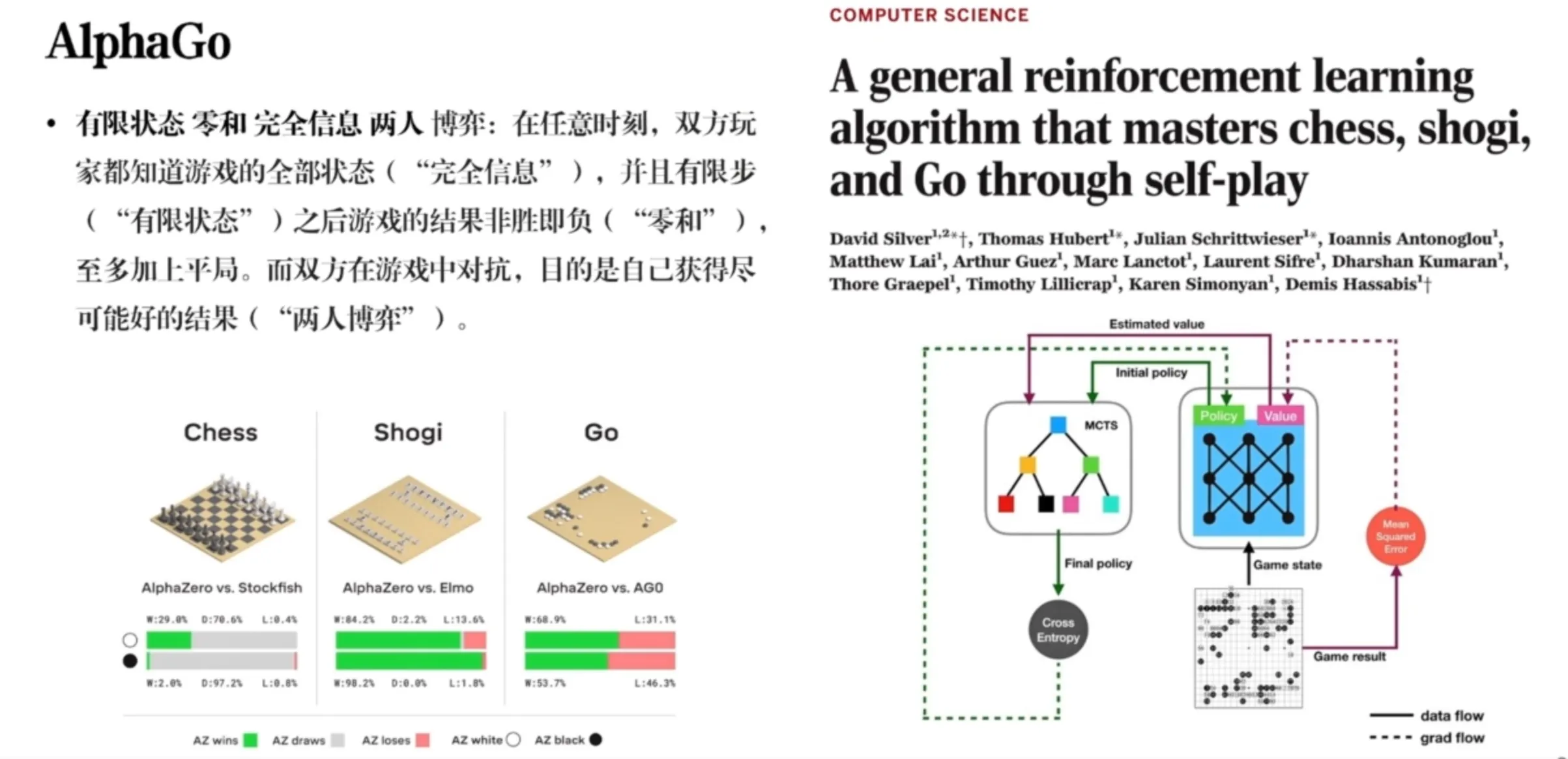
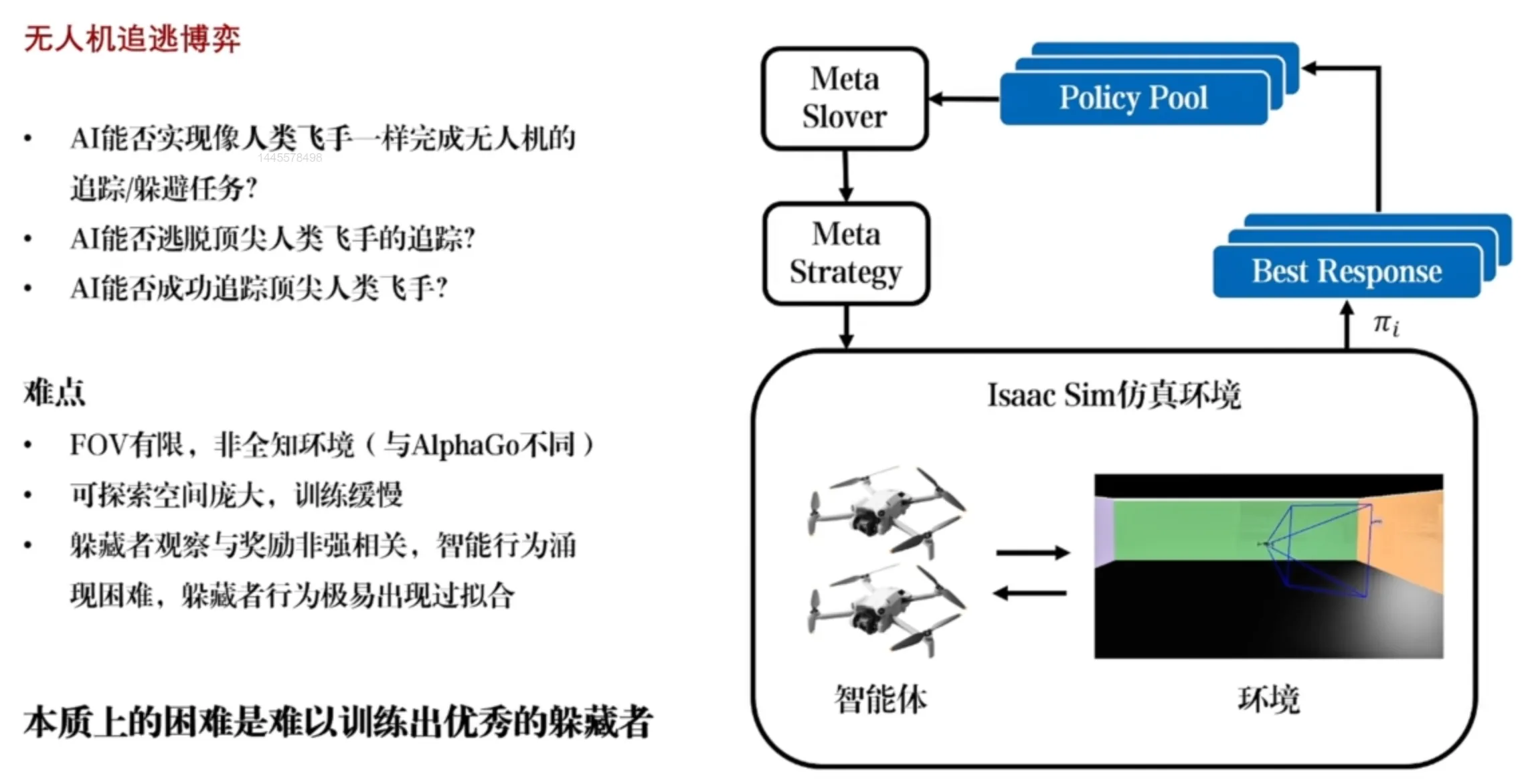
Classic RL + Game-Theoretic Algorithm - PSRO#
Trained RL policies should generalize well; during training, be careful to avoid overfitting (especially overfitting to a specific opponent strategy).
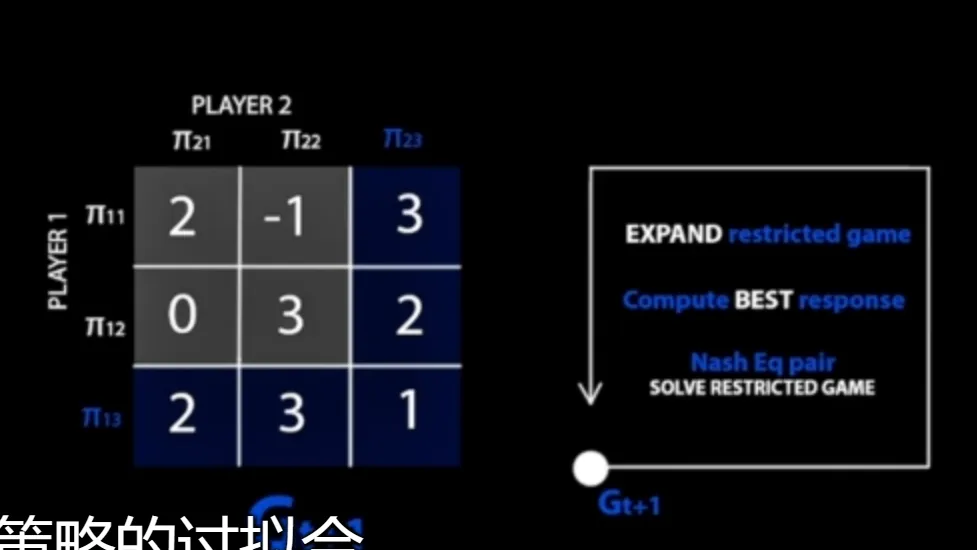
PSRO workflow: Instead of a single pursuer policy and a single evader policy, PSRO maintains a policy pool: multiple different pursuers and multiple different evaders. When training one side, we sample an opponent from the opponent’s policy pool, which maintains opponent diversity. We then fix the sampled opponent policy and keep training our policy until convergence, so that our policy becomes an approximate best response given other players’ policies fixed. We then add it to that player’s policy pool. By iterating this game-training process, both evaders and pursuers improve, and the diversity of opponent strategies helps ensure policies are more general and have better generalization.

Applications of Reinforcement Learning in High-Maneuver Flight#
Vision-based flight through narrow gaps: The network takes images as input, encodes them with a visual encoder, and directly outputs control commands (angular velocity and thrust). One challenge is that images are high-dimensional. Asking a network to learn both perception/understanding and high-precision motion control from scratch is difficult: it needs lots of data, and exploration in the solution space is inefficient.
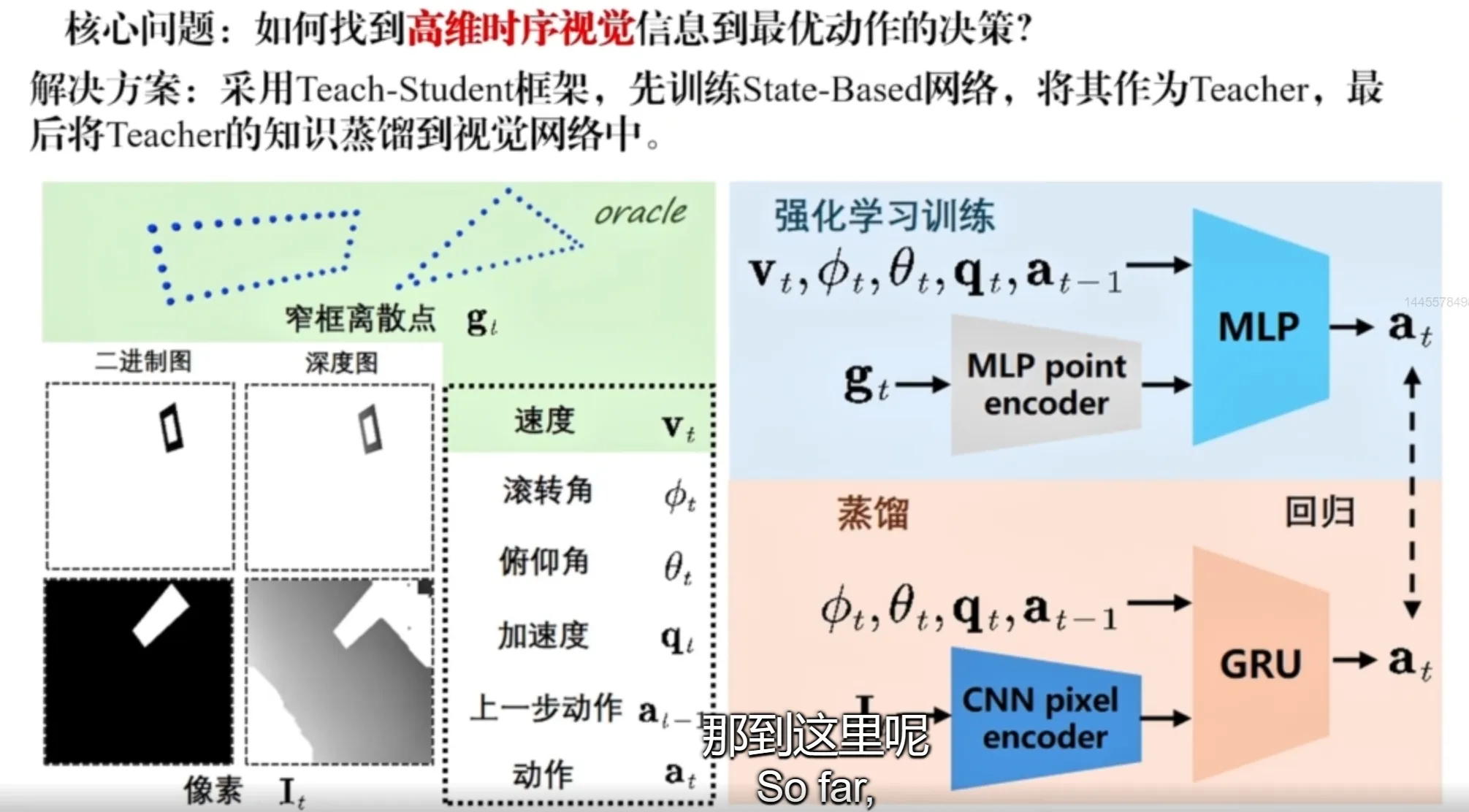
Method: Use a teach-student framework. Extract the corner points of the frame (narrow gap) that the UAV should fly through, and train a teacher that only focuses on motion control. Then, via online distillation, supervise the student by matching the teacher’s outputs and the student’s outputs, obtaining the student network for real use. This provides a clearer direction for evolution and significantly improves learning efficiency. The network structure also uses a GRU (an RNN structure), so the trained policy has memory of perceptual data (because the network implicitly needs to estimate and recognize the narrow gap). Multi-frame information is better than single-frame information, and the policy can use previous memory (past observations) to complete subsequent actions.
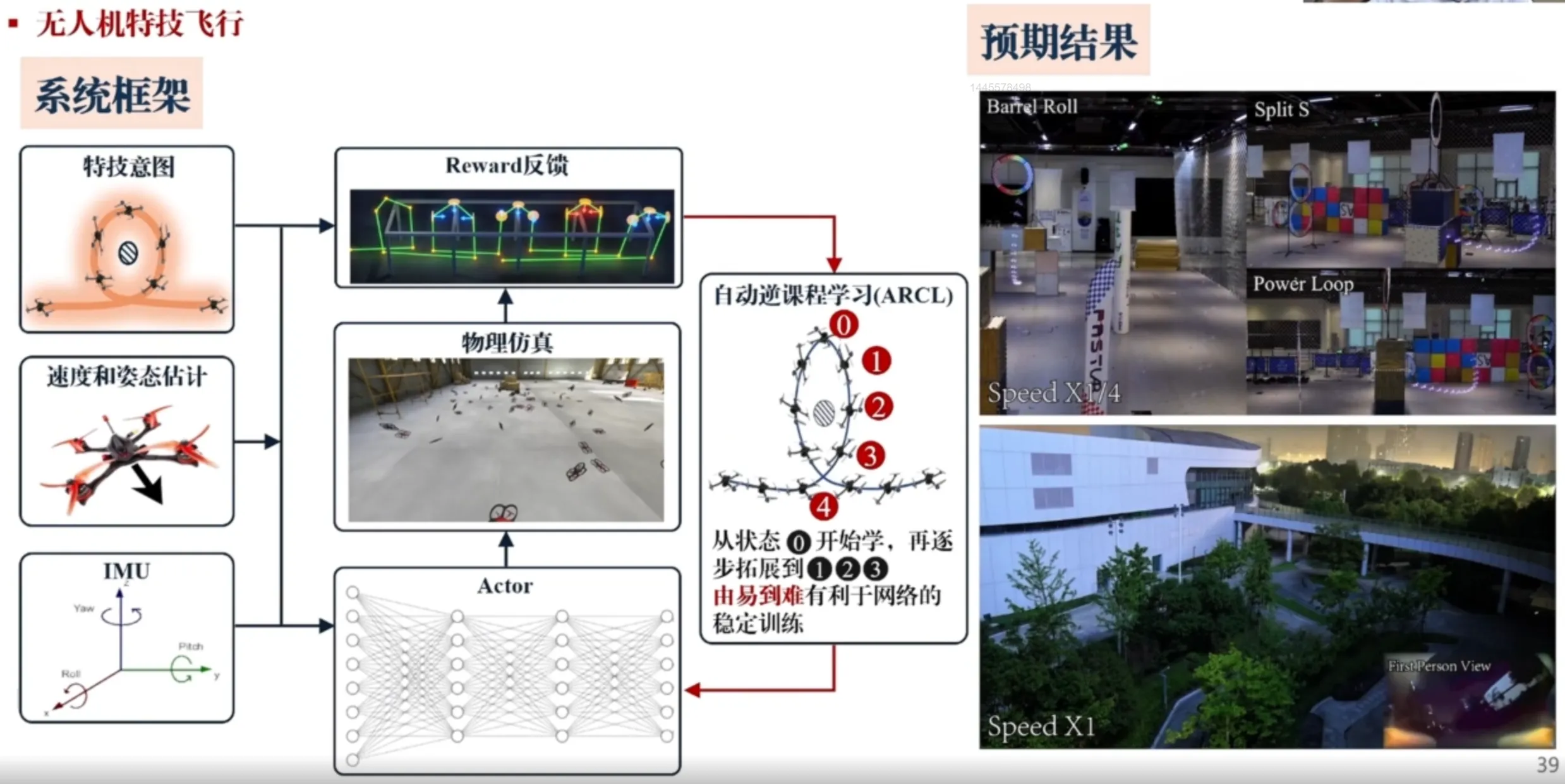
UAV aerobatic flight - Automatic Reverse Curriculum Learning (ARCL)