
Paper Reading: Robot learning 3
I want to stand with them.
RL-BASED DRONE PAPER READING
Large-scale RL Exploration#
Privileged RL + attention-map networks with graph sparsification for large-scale scenes
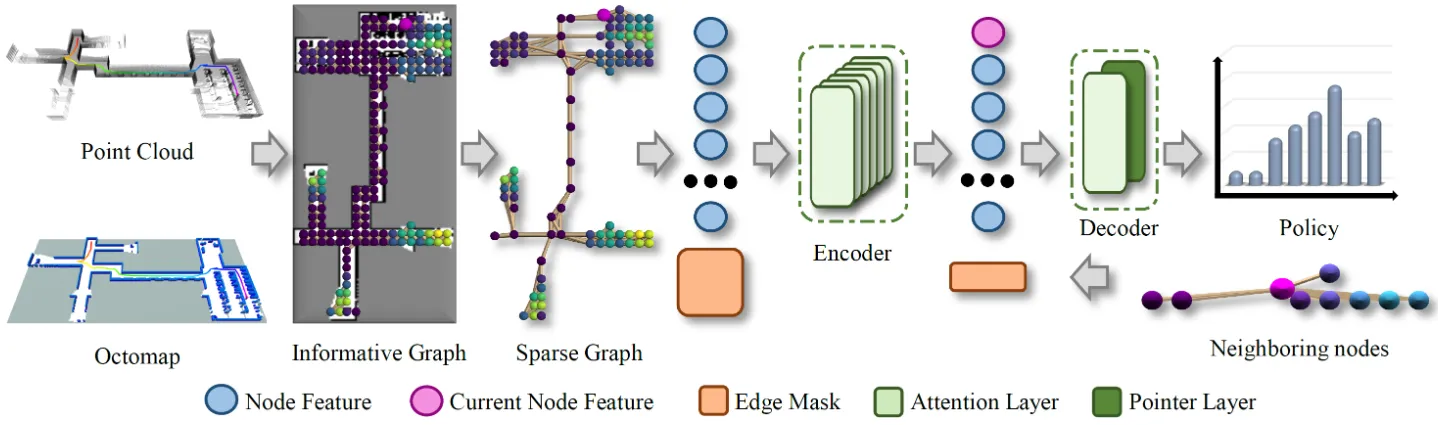 A deep RL exploration planner for large-scale environments. It uses privileged learning so the critic network can access true environment information to evaluate policies more accurately, combines an attention-map network to capture multi-scale spatial dependencies, and uses a graph-sparsification algorithm so a model trained in small scenes can be directly applied to large-scale environments. Simulation and real-world tests show better path length, time cost, and planning speed than frontier methods such as TARE.
A deep RL exploration planner for large-scale environments. It uses privileged learning so the critic network can access true environment information to evaluate policies more accurately, combines an attention-map network to capture multi-scale spatial dependencies, and uses a graph-sparsification algorithm so a model trained in small scenes can be directly applied to large-scale environments. Simulation and real-world tests show better path length, time cost, and planning speed than frontier methods such as TARE.
Agile Flight from Pixels#
Asymmetric actor-critic + gate-inner-edge visual abstraction + pixel-to-control without explicit state estimation
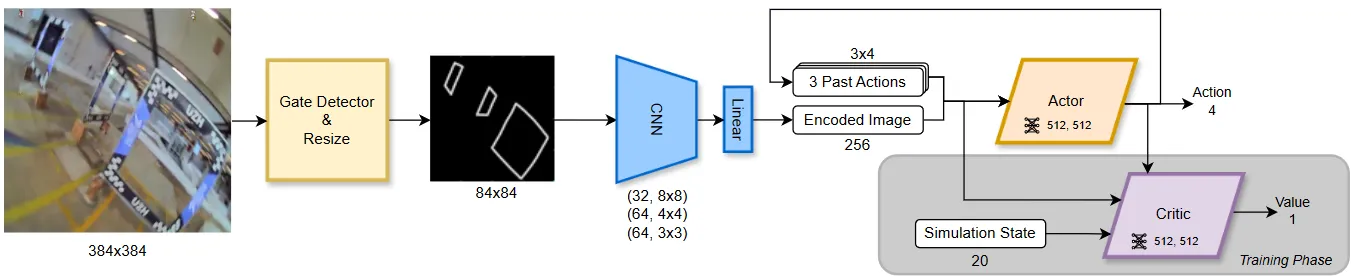 This paper presents the first vision-based agile quadrotor flight system without explicit state estimation. It uses an asymmetric actor-critic framework where the critic gets privileged state information to improve training, uses inner edges of racing gates as a visual abstraction to simplify pixel-level RL training, and combines a SwinTransformer gate detector. With only an onboard camera video stream, it achieves racing flight up to 40 km/h and 2g acceleration, with zero-shot sim-to-real transfer.
This paper presents the first vision-based agile quadrotor flight system without explicit state estimation. It uses an asymmetric actor-critic framework where the critic gets privileged state information to improve training, uses inner edges of racing gates as a visual abstraction to simplify pixel-level RL training, and combines a SwinTransformer gate detector. With only an onboard camera video stream, it achieves racing flight up to 40 km/h and 2g acceleration, with zero-shot sim-to-real transfer.
HOLA-Drone#
Hypergraph open-ended learning + zero-shot coordination for pursuit with unknown teammate drones
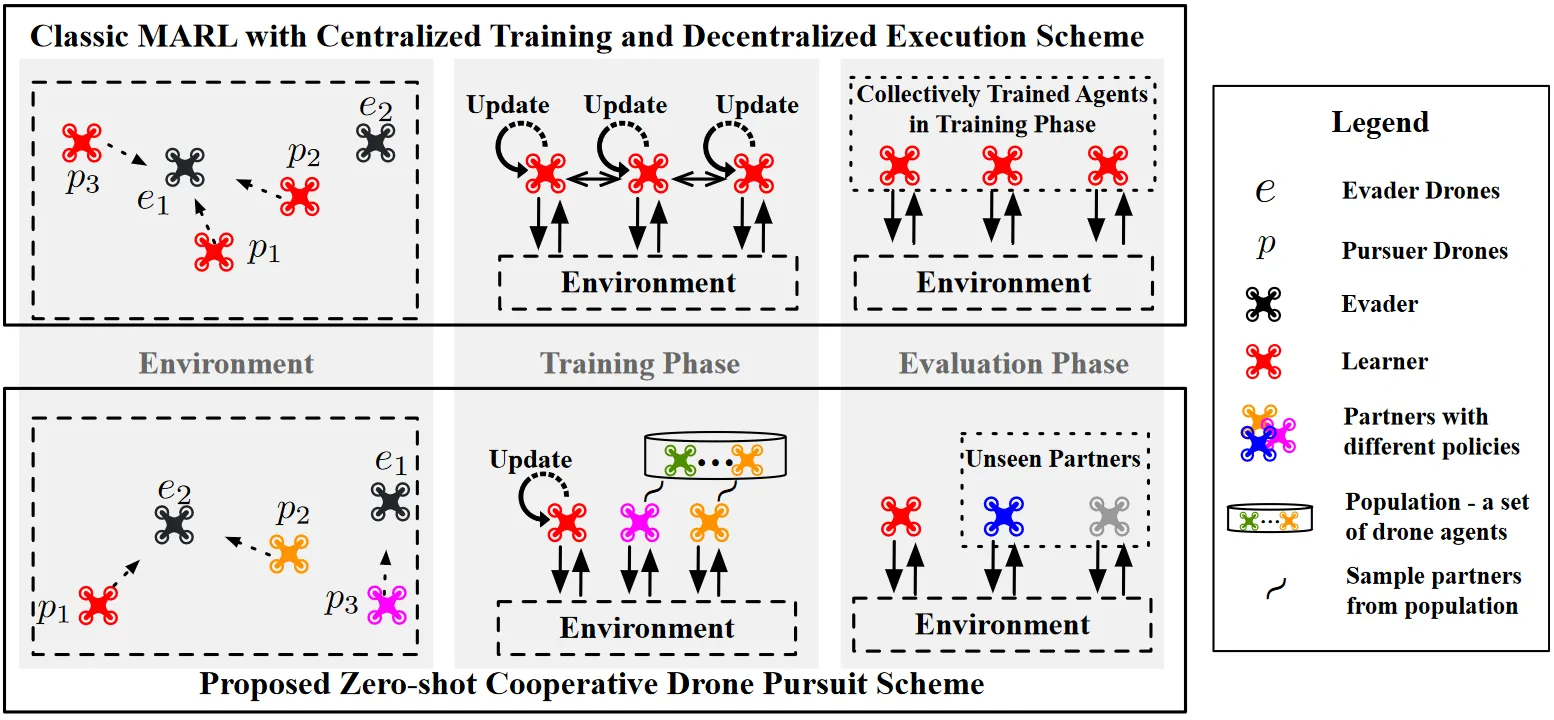 It models multi-UAV cooperative pursuit as a zero-shot coordination problem and proposes HOLA-Drone, a hypergraph open-ended learning algorithm. It formalizes multi-agent interaction relationships with hypergraphs, adaptively adjusts learning objectives to strengthen collaboration with unknown teammates. Simulation and real-world experiments show significantly higher capture success rate and efficiency than baselines such as self-play and population training, in both homogeneous and heterogeneous unknown-teammate settings.
It models multi-UAV cooperative pursuit as a zero-shot coordination problem and proposes HOLA-Drone, a hypergraph open-ended learning algorithm. It formalizes multi-agent interaction relationships with hypergraphs, adaptively adjusts learning objectives to strengthen collaboration with unknown teammates. Simulation and real-world experiments show significantly higher capture success rate and efficiency than baselines such as self-play and population training, in both homogeneous and heterogeneous unknown-teammate settings.
OmniDrones#
A UAV RL platform with GPU-parallel simulation for multiple models and tasks
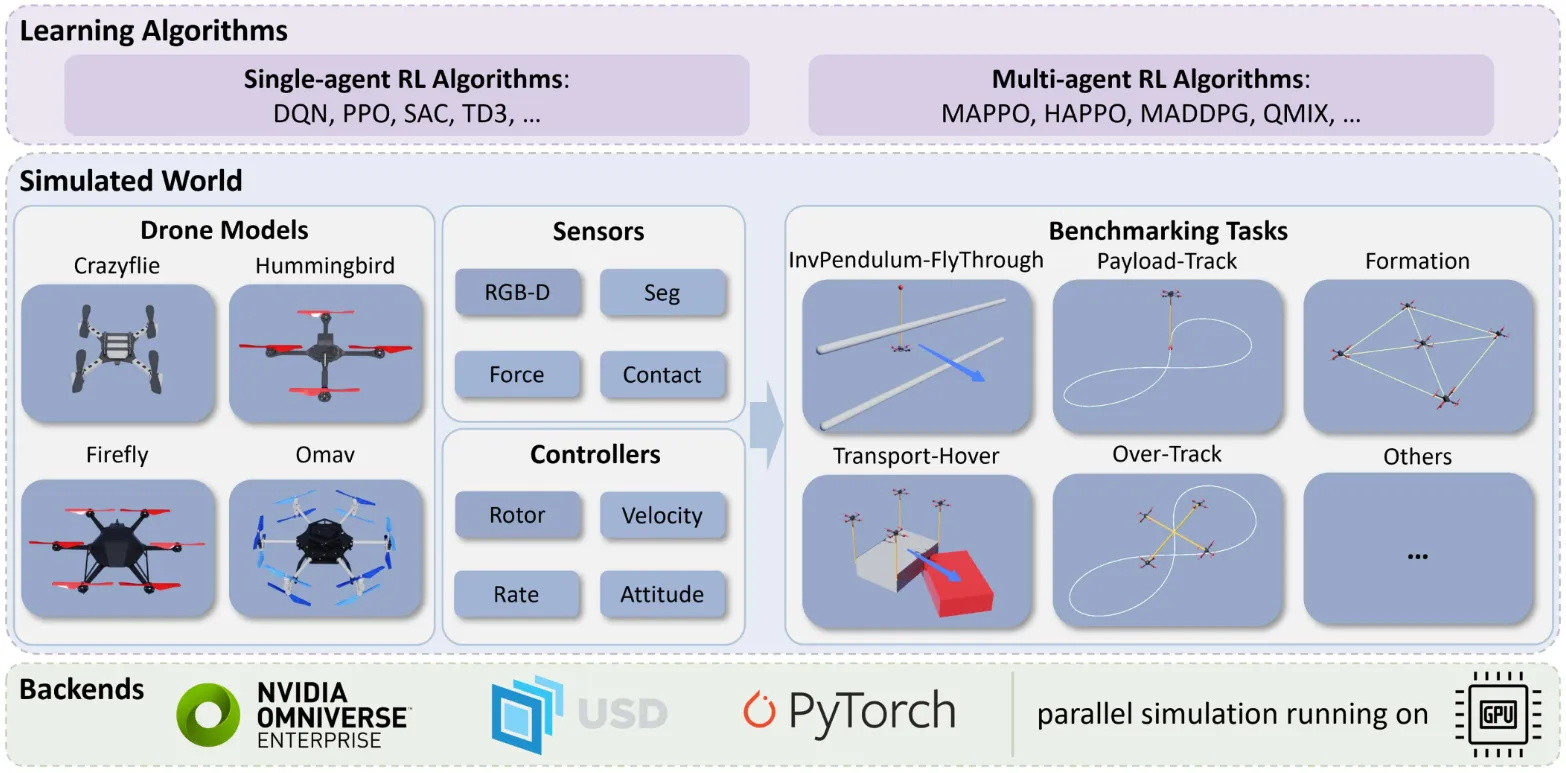 OmniDrones is built on NVIDIA Omniverse Isaac Sim as a UAV reinforcement learning platform. It uses PyTorch to parallelize dynamics computation on GPU to improve sampling efficiency, supports 4 UAV types, 5 sensors, 4 control modes, and 10+ benchmark tasks, and is compatible with mainstream single-/multi-agent RL algorithms. It provides an efficient, scalable, and customizable simulation and evaluation environment for learning UAV control.
OmniDrones is built on NVIDIA Omniverse Isaac Sim as a UAV reinforcement learning platform. It uses PyTorch to parallelize dynamics computation on GPU to improve sampling efficiency, supports 4 UAV types, 5 sensors, 4 control modes, and 10+ benchmark tasks, and is compatible with mainstream single-/multi-agent RL algorithms. It provides an efficient, scalable, and customizable simulation and evaluation environment for learning UAV control.
Multi-UAV Pursuit-Evasion#
Evasion prediction network + adaptive environment generation + two-stage rewards for pursuit-evasion in unknown environments
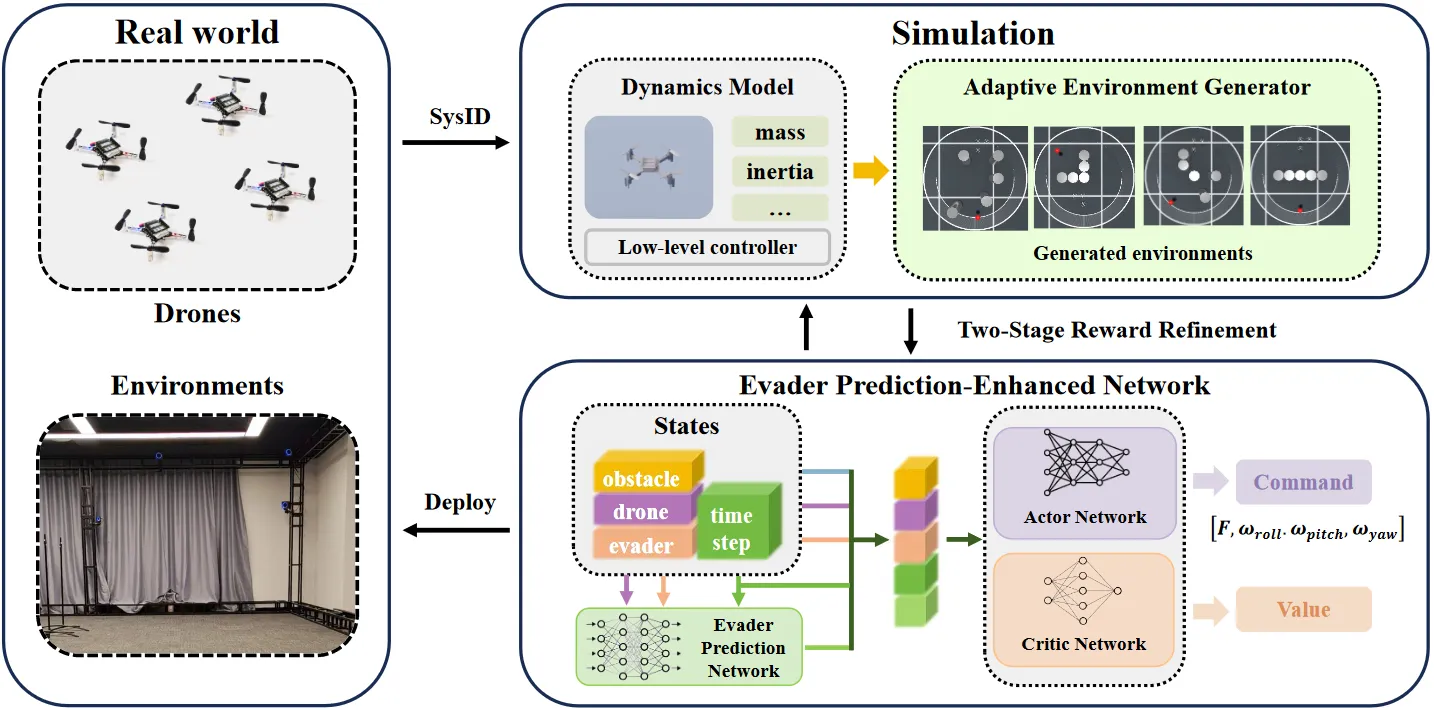 For multi-UAV pursuit-evasion in unknown environments, it proposes an evader prediction-enhanced network to handle partial observability, combines an adaptive environment generator to improve policy generalization and sample efficiency, and uses two-stage rewards to refine commands for smooth, deployable control. In simulation it achieves 100% capture rate in unknown scenes and outperforms all baselines. It is also among the first to deploy an RL policy (outputting total thrust and body angular rates) zero-shot to a real quadrotor to complete pursuit-evasion tasks.
For multi-UAV pursuit-evasion in unknown environments, it proposes an evader prediction-enhanced network to handle partial observability, combines an adaptive environment generator to improve policy generalization and sample efficiency, and uses two-stage rewards to refine commands for smooth, deployable control. In simulation it achieves 100% capture rate in unknown scenes and outperforms all baselines. It is also among the first to deploy an RL policy (outputting total thrust and body angular rates) zero-shot to a real quadrotor to complete pursuit-evasion tasks.
PKCC#
Learned kinematics correction + weight-allocation MPC for high-precision aerial manipulator coordination
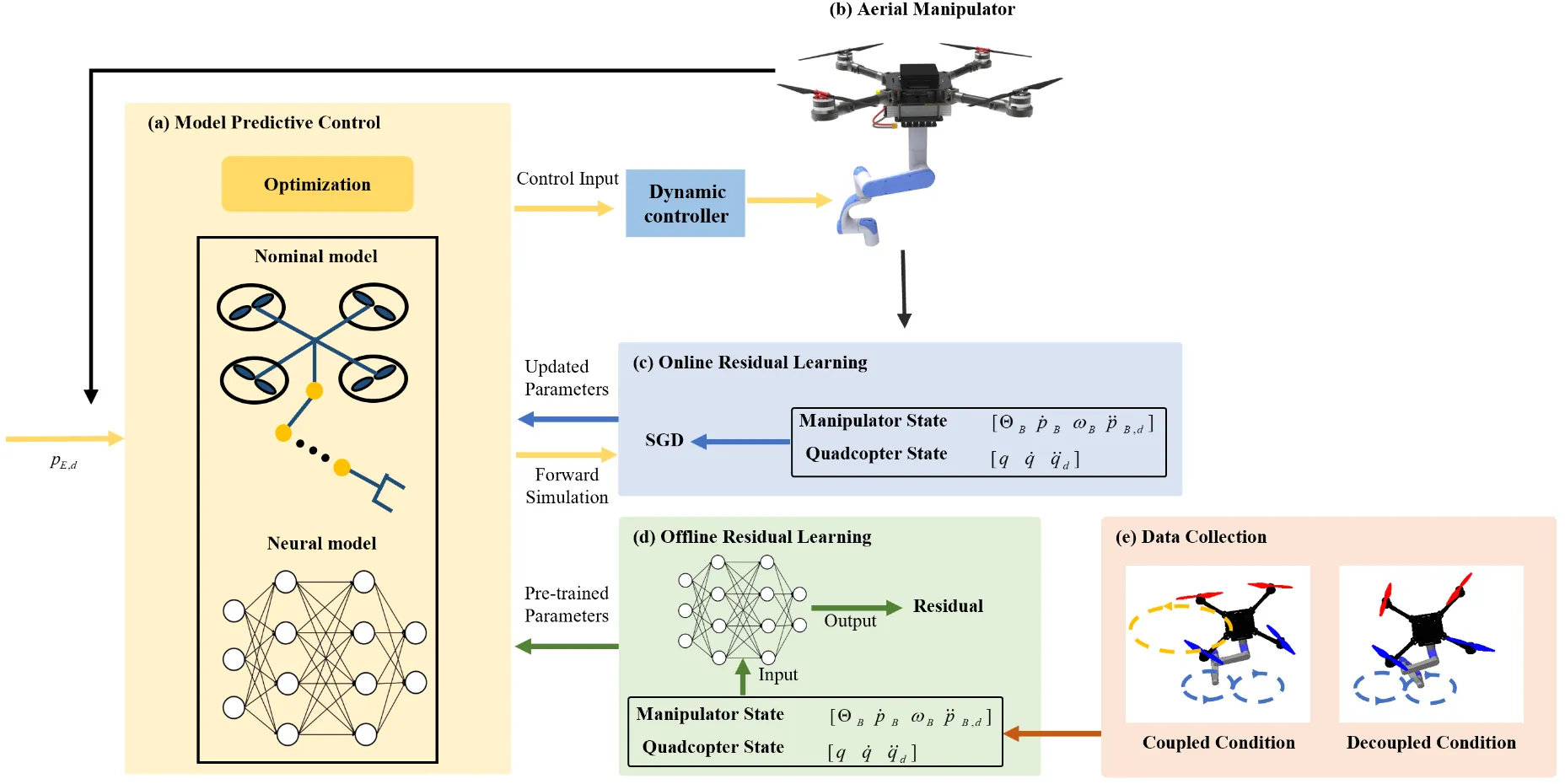 To address low accuracy and difficult motion allocation in aerial manipulator kinematic control, it proposes a predictive kinematic cooperative control method. It builds a corrected kinematics model that incorporates closed-loop dynamics and online residual learning to improve modeling accuracy, and designs a weight-allocation MPC to coordinate motion strategies between the UAV and robotic arm. Experiments show a 59.6% improvement in trajectory tracking accuracy, enabling complex-trajectory and moving-target tracking.
To address low accuracy and difficult motion allocation in aerial manipulator kinematic control, it proposes a predictive kinematic cooperative control method. It builds a corrected kinematics model that incorporates closed-loop dynamics and online residual learning to improve modeling accuracy, and designs a weight-allocation MPC to coordinate motion strategies between the UAV and robotic arm. Experiments show a 59.6% improvement in trajectory tracking accuracy, enabling complex-trajectory and moving-target tracking.
Pixel Motion#
Monocular optical flow + central-flow attention + differentiable simulation for high-speed quadrotor obstacle avoidance
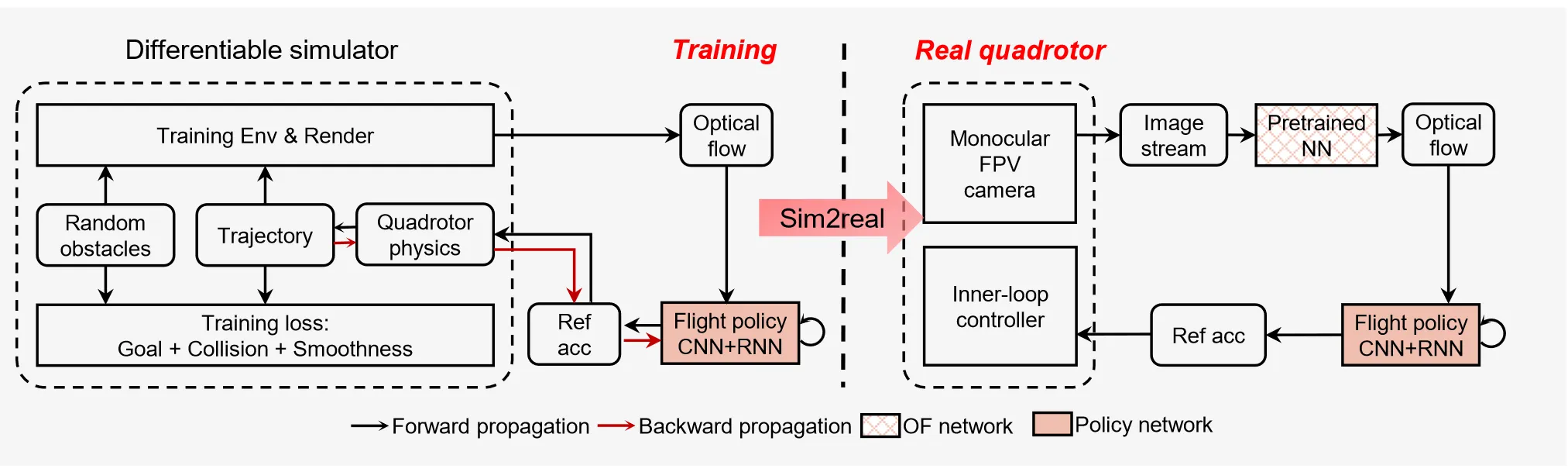 For monocular-vision quadrotor obstacle avoidance, it proposes an optical-flow-based end-to-end learning framework. Policy training is done via differentiable simulation, introducing central-flow attention and an action-guided active-perception mechanism to strengthen extraction of key visual information. With only a monocular FPV camera, it achieves agile obstacle avoidance up to 6 m/s in unknown cluttered environments, with zero-shot sim-to-real transfer.
For monocular-vision quadrotor obstacle avoidance, it proposes an optical-flow-based end-to-end learning framework. Policy training is done via differentiable simulation, introducing central-flow attention and an action-guided active-perception mechanism to strengthen extraction of key visual information. With only a monocular FPV camera, it achieves agile obstacle avoidance up to 6 m/s in unknown cluttered environments, with zero-shot sim-to-real transfer.
Simple Flight#
PPO + five key design dimensions for zero-shot sim2real transfer control on quadrotors
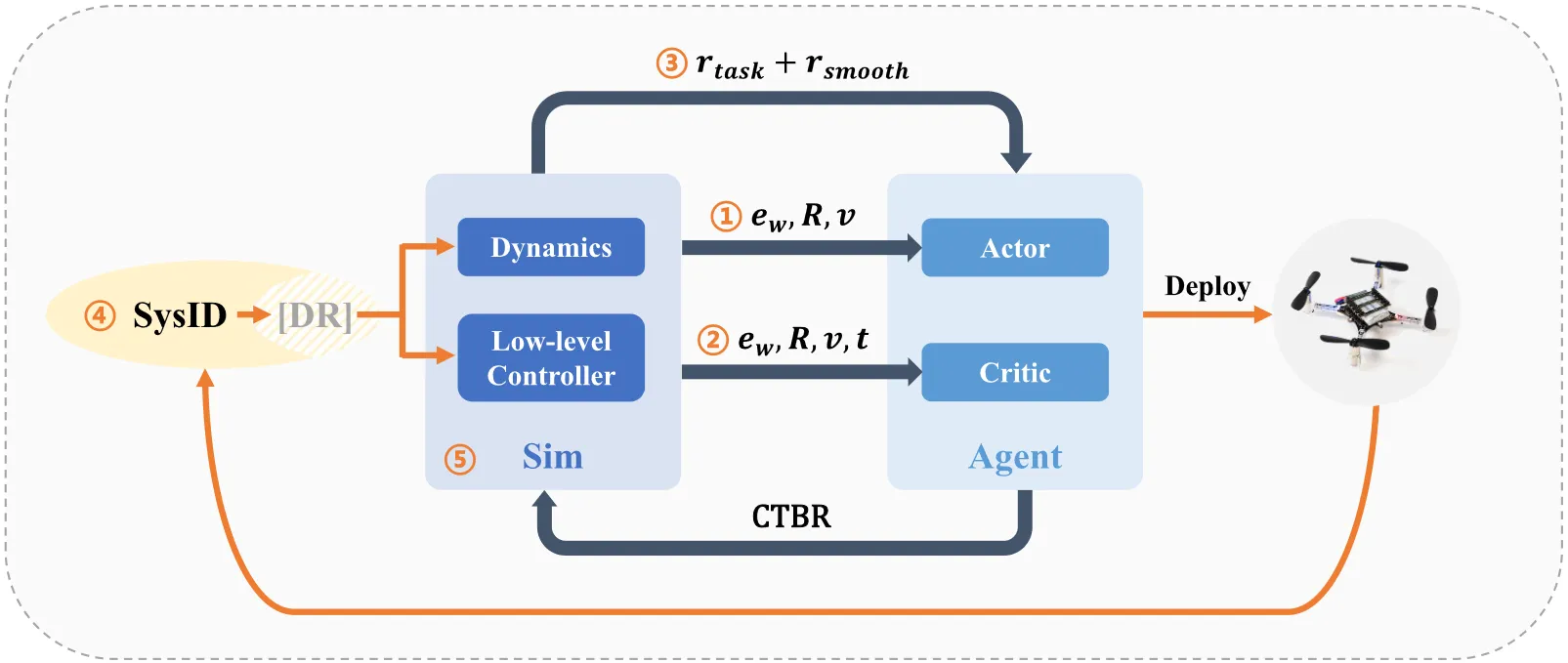 It distills five core elements for zero-shot deployment of RL on quadrotors. Based on PPO, it builds the SimpleFlight framework and optimizes observation inputs, reward smoothing, system identification and selective domain randomization, and large-batch training. On nano drones, trajectory tracking error is reduced by over 50%, enabling stable tracking of smooth and infeasible trajectories and cross-platform generalization.
It distills five core elements for zero-shot deployment of RL on quadrotors. Based on PPO, it builds the SimpleFlight framework and optimizes observation inputs, reward smoothing, system identification and selective domain randomization, and large-batch training. On nano drones, trajectory tracking error is reduced by over 50%, enabling stable tracking of smooth and infeasible trajectories and cross-platform generalization.
Whole-Body Control Gap#
RL + observation distillation + informed resets for pixel-to-action whole-body narrow-gap traversal
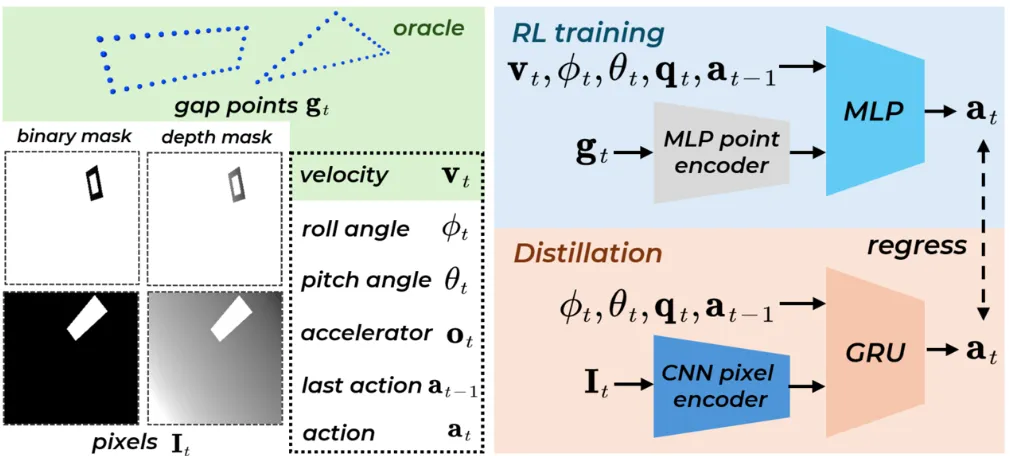 End-to-end narrow-gap whole-body control from pixels to actions for a quadrotor. It uses model-free RL to learn a low-dimensional point-cloud policy, then transfers to high-dimensional pixel input via online observation distillation. It proposes informed resets to mitigate sparse-exploration difficulty, enabling body-level narrow-gap traversal across many geometries and large attitudes without hand-crafted curricula.
End-to-end narrow-gap whole-body control from pixels to actions for a quadrotor. It uses model-free RL to learn a low-dimensional point-cloud policy, then transfers to high-dimensional pixel input via online observation distillation. It proposes informed resets to mitigate sparse-exploration difficulty, enabling body-level narrow-gap traversal across many geometries and large attitudes without hand-crafted curricula.
YOPO#
Single-stage planning + guided learning + motion primitives for real-time mapless quadrotor trajectories
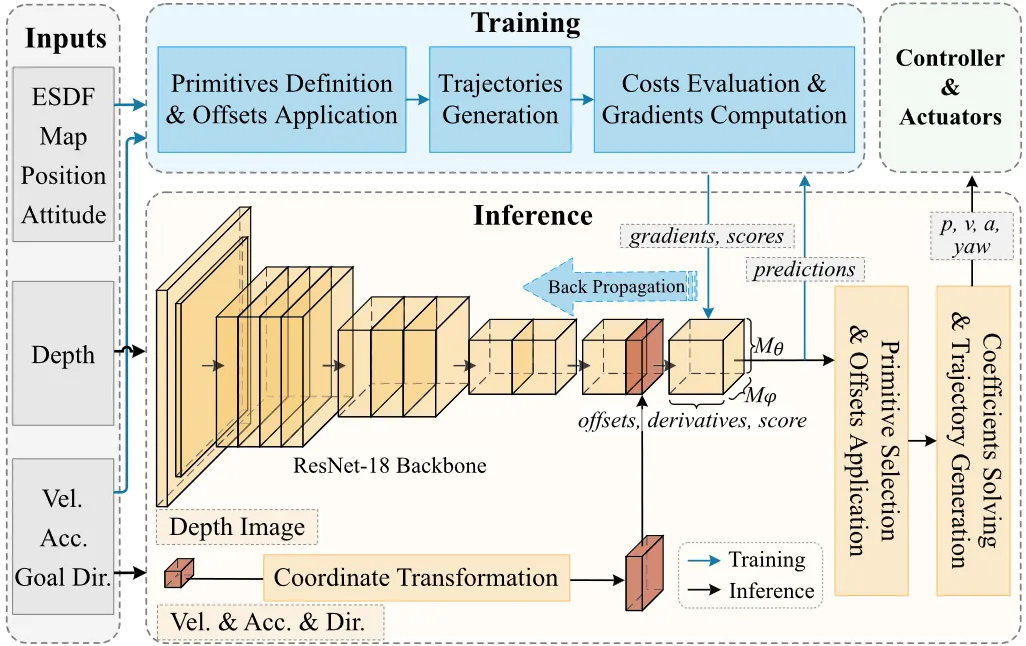 YOPO is a single-stage learning-based planner for quadrotors that fuses perception, path search, and trajectory optimization into a single network. It covers the planning solution space with motion primitives, and uses an innovative guided-learning method to train the network with numerical gradients. Inference latency is only 1.6 ms. Simulation and real-world experiments demonstrate high-speed safe flight in complex forest environments, outperforming traditional gradient-optimization methods.
YOPO is a single-stage learning-based planner for quadrotors that fuses perception, path search, and trajectory optimization into a single network. It covers the planning solution space with motion primitives, and uses an innovative guided-learning method to train the network with numerical gradients. Inference latency is only 1.6 ms. Simulation and real-world experiments demonstrate high-speed safe flight in complex forest environments, outperforming traditional gradient-optimization methods.