前言#
传统方法实现无人机自主导航和智能飞行#
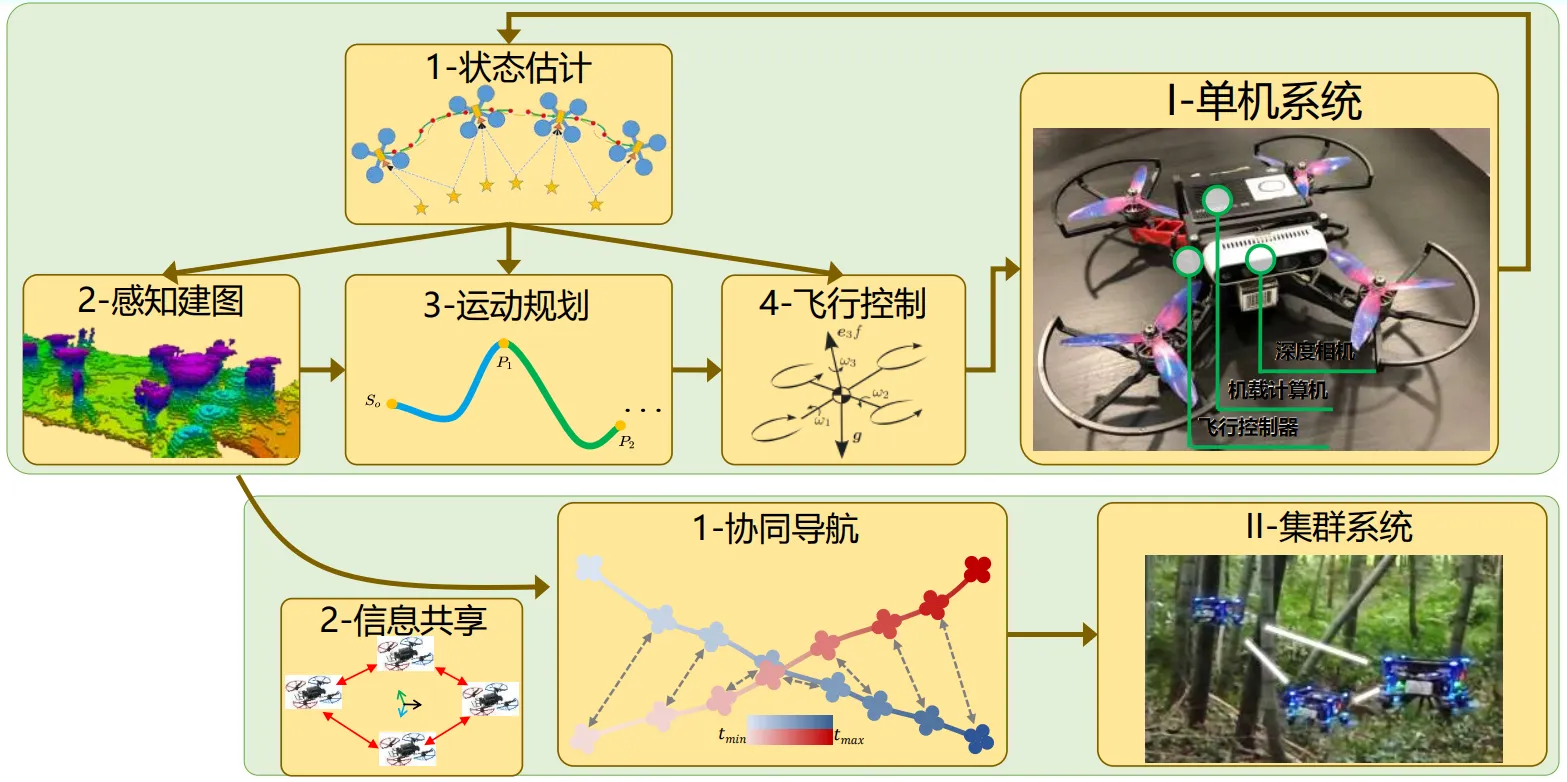
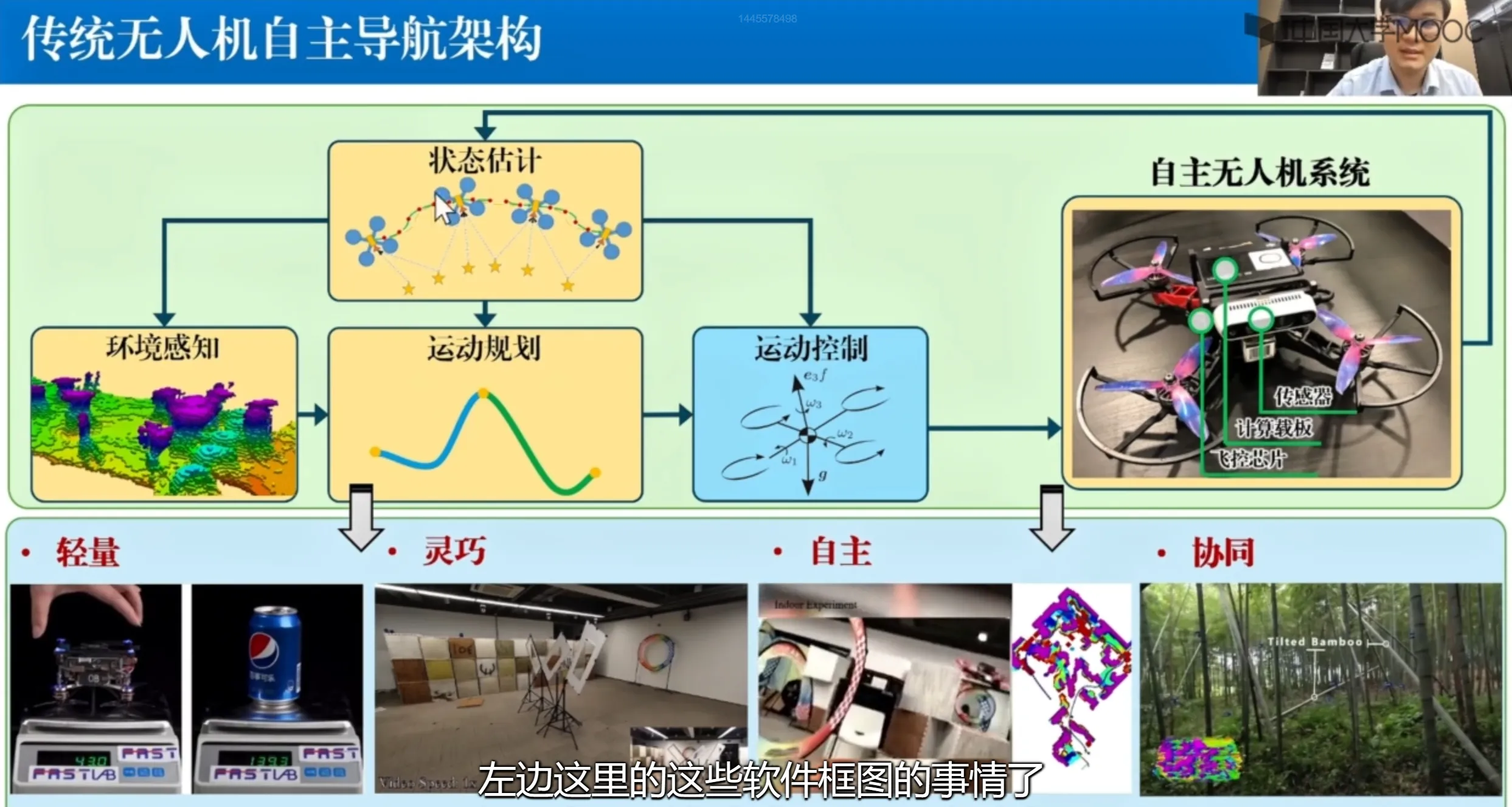
自主导航是无人机自主化的关键基石,是需要攻关的核心技术。传统无人机自主导航框架主要如下所示。
-
状态估计:无人机根据环境中的图片或其他传感器信息去推算出自己当前的一个状态,这个状态包括了位置、姿态、速度及角速度等高阶的运动状态。
-
环境感知:基于估计出的状态,再次结合环境中采集到的传感器数据,做一个对环境的三维重建,让无人机知道哪些地方可以通行哪些可能是这次任务感兴趣的兴趣点,构建出一个三维的高精度的态势地图。
-
运动规划:基于构建出的地图和自身状态的推断来做运动规划,这个规划要有两个要求一个是安全(无人机不能撞到东西),一个是可行(这个规划出的路径要是物理有意义的)。
-
运动控制:保证我的无人机处于一个平稳飞行状态,速度要达到期望的速度,姿态要尽可能的平稳。在机载计算载板计算完成之后下发到整个电机,具体转速的指令通过底层飞控芯片发下去。
-
something else:可以看到这些都是一些模块化开发的东西,彼此之间是比较独立的。坏处也很明显,模块和模块之间很难协同优化。
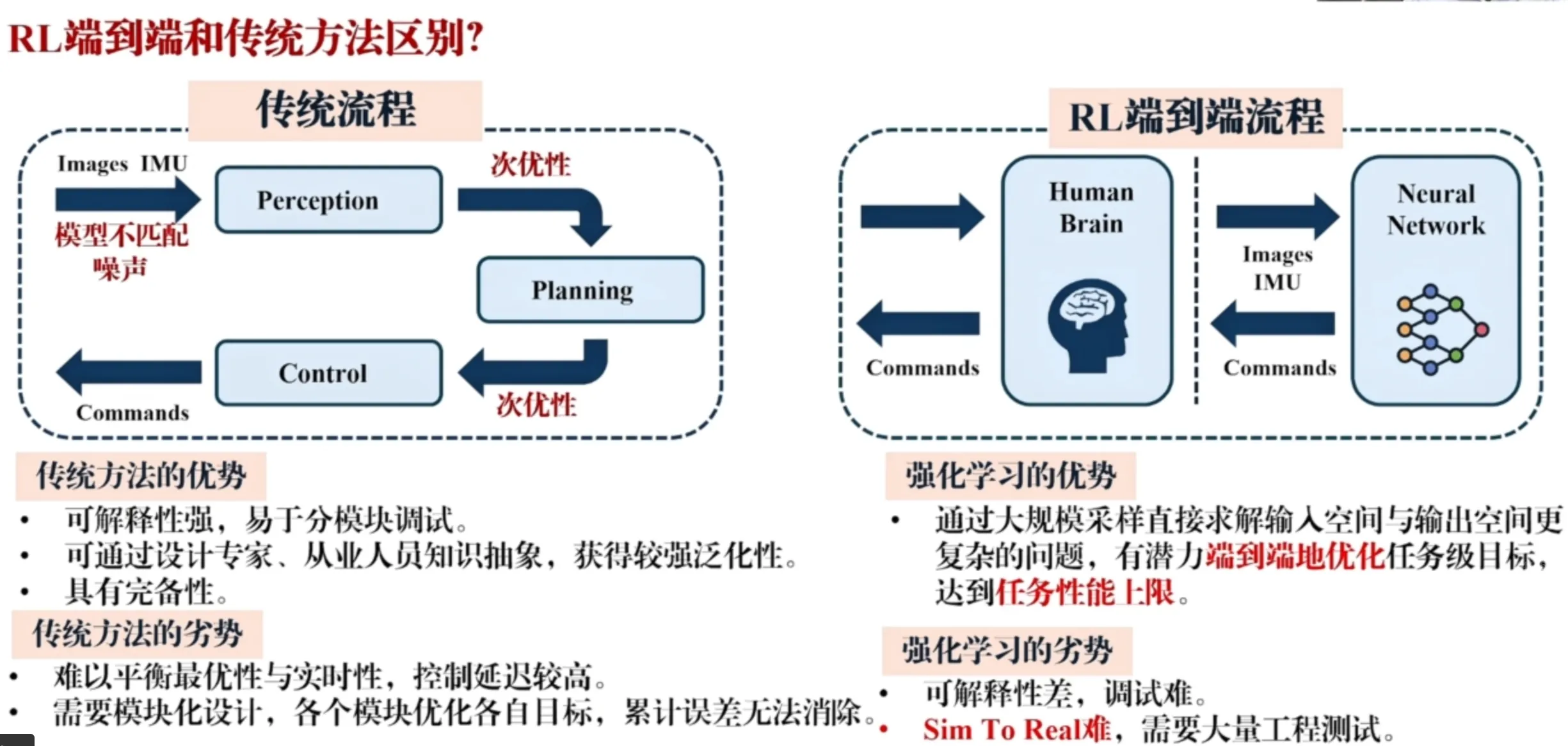
RL端到端和传统方法的区别#
强化学习的方法没有,先进行感知构建一个地图再在上面进行轨迹规划,再沿着规划的轨迹去做控制这一个过程。实际上的一整个过程是一个闭环,是一个端到端的过程了,前面一端传感器采集数据,后面一端即为控制指令。
从本质上看就是在系统层面的对导航算法的优化。与传统模块化开发的算法在一个复杂系统中,即便他达到了局部最优,那当他们连在一起时也不能说明他达到了系统上的全局最优。因为模块和模块之间的梯度是不能流淌的、不连通的。
RL 端到端的方法是直接优化整个模型,用一个模型就完全完成了一端到另一端的问题,理论上限是更高的。RL 的网络更加轻量,通过利用离线大量算力和计算时间,获得在线的推.理效率。(传统方法需要有很强的在线的优化和专用的数学求解工具),那么 RL 就可以得到更高的计算效率和更低的对机载芯片的功耗和造价的要求。
传统方法的分模块化设计会出现累计误差(例如视觉传感器,他一定会有噪声和定位误差的,那么在后面建图与规划的过程中误差就会累计,让整个系统的表现变差)。
传统方法的优势:每个模块都是精心设计的,是透明的,可解释性强,易于分模块调试(知道问题出现在哪个模块上)。
RL 方法的劣势:黑盒,整个系统就是一个模型,可能系统全部都能 work,也可能全部都不能 work,调试开发难度大。sim to real 和 real to sim 需要大量的工程测试和一些实际部署上的技巧。
结合传统方法与强化学习(更完备、泛化性更强)#
把强化学习网络的一部分换成一个轨迹规划器(比以往完全是一个黑盒要好)。
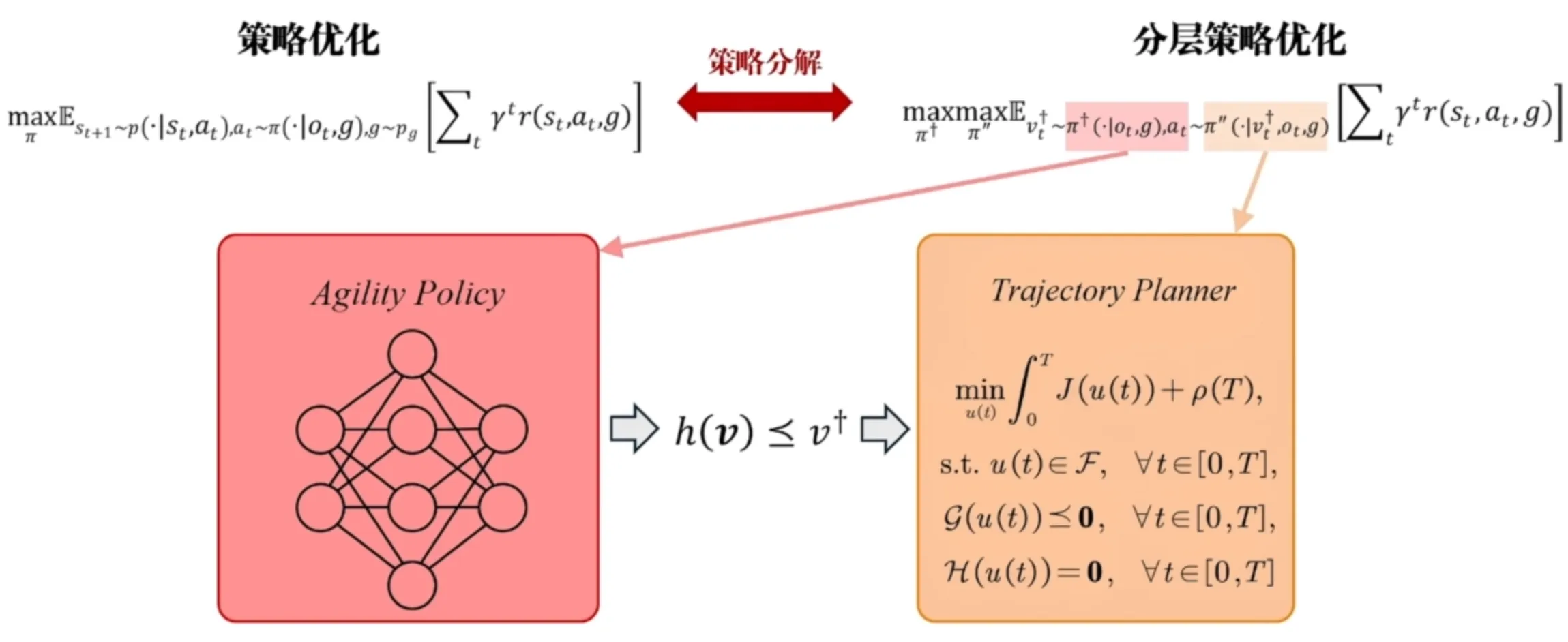
如果是原来完全强化学习的方法,更改目标函数之后可能就会要重新去训练强化学习网络。但现在我引入了轨迹优化的方法,就可以只通过改变轨迹优化的目标函数来实现对网络的调整。
基于强化学习的自适应导航框架:强化学习输出的是轨迹优化所需要的参数,具体来说是最大速度(速度上限)。用强化学习做无人机飞行的自动调速器(当感知到障碍物环境复杂和视觉盲区的时候无人机是可以稍微降低速度的,保证安全)。

强化学习在无人机追逃博弈中的应用#
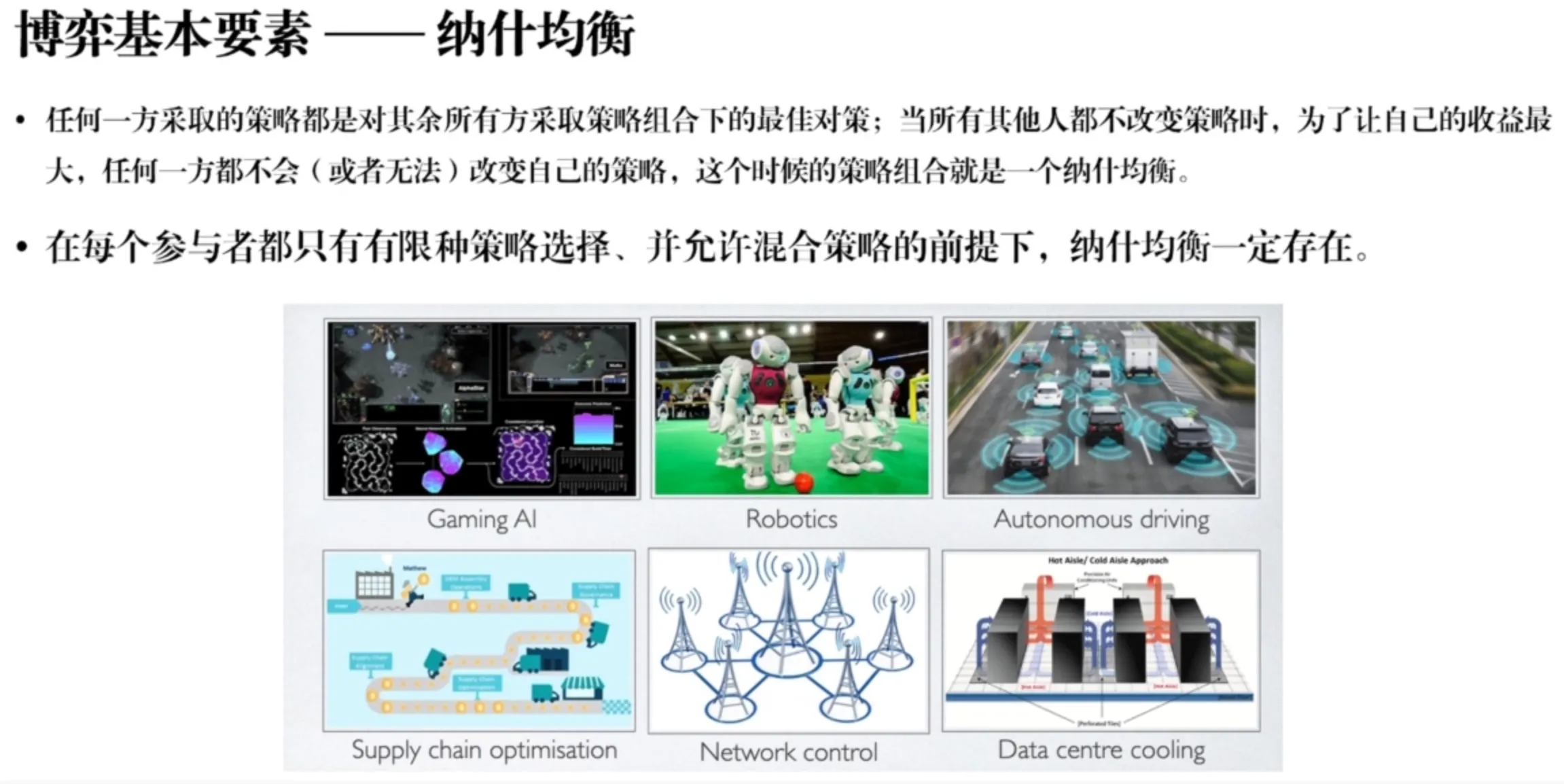
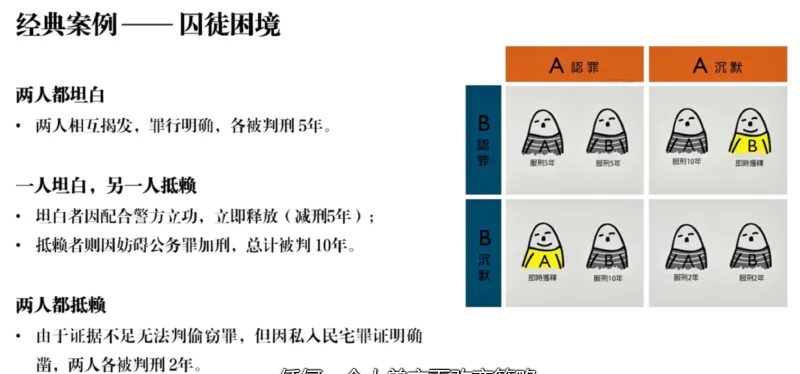
博弈的基本要素与概念。
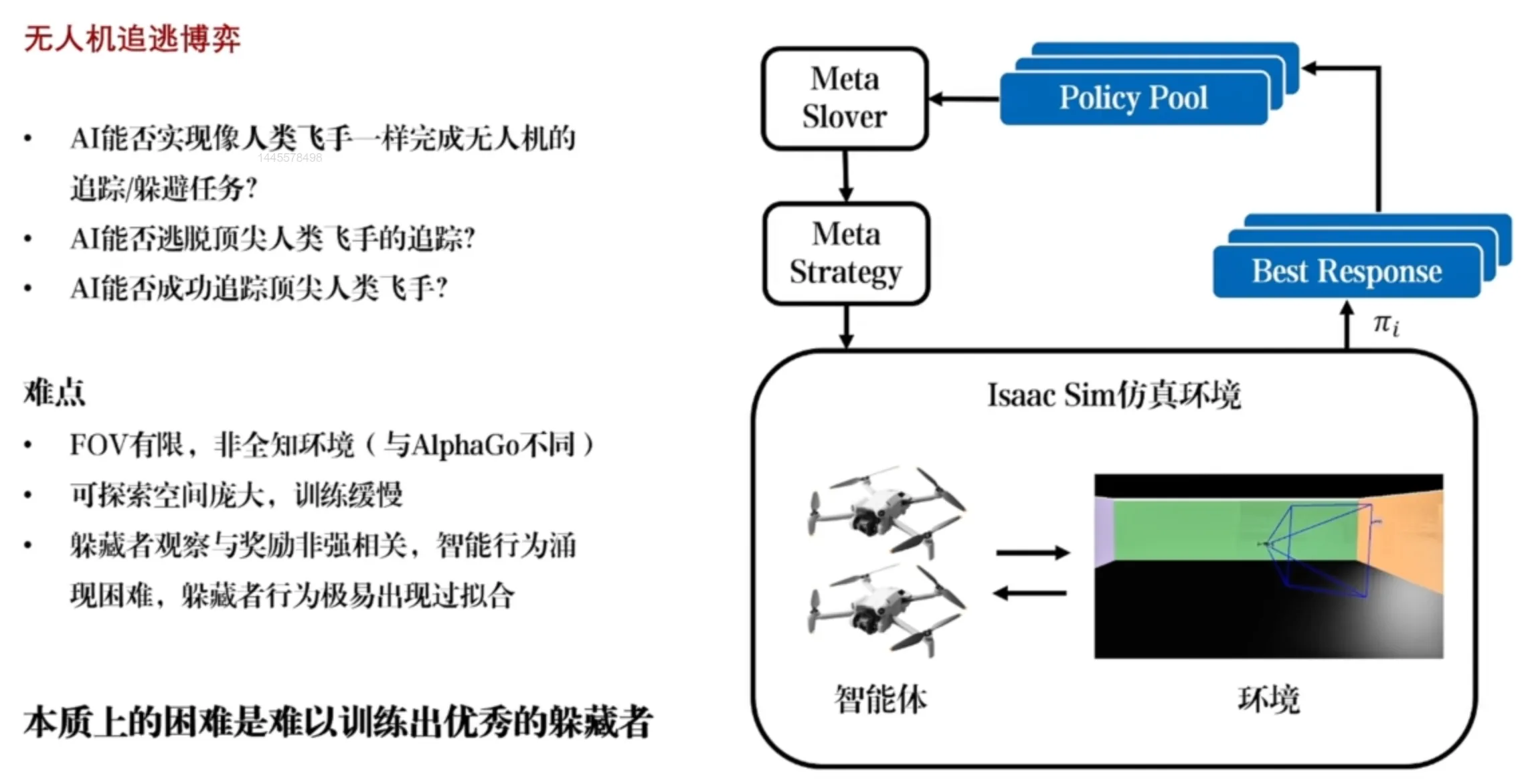
经典 RL + 博弈算法 —— PSRO#
训练出的 RL 算法要具有泛化性,注意在训练的时候不要出现过拟合的现象(不是针对特定对手策略的过拟合)。
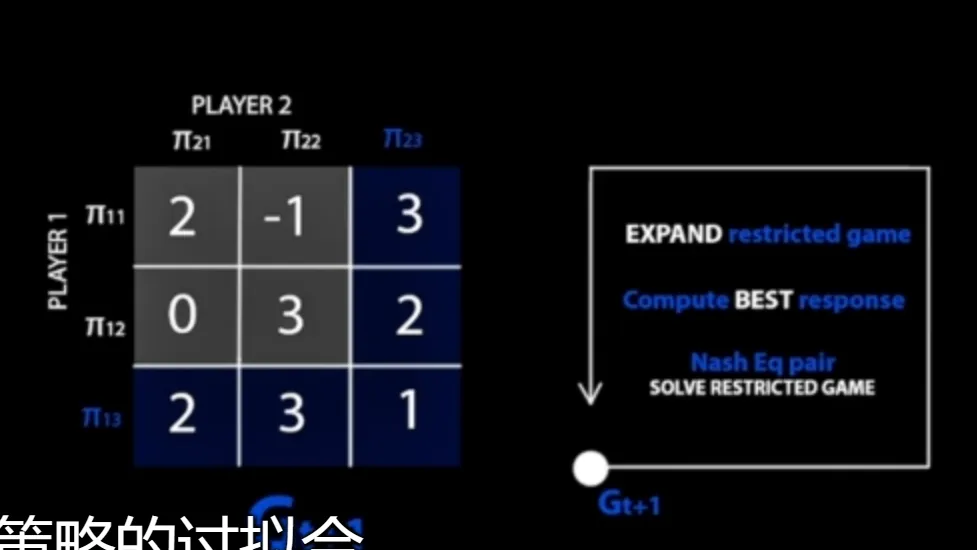
PSRO 的流程:他不是单一的追逐者策略和逃跑者策略,而是维护了一个策略池,相当于有多个不同的追逐者,和多个不同的逃跑者,在训练其中一方时,我们从对手的策略池中,采样一个作为对手,这样就保持了对手的多样性,从对手的策略池中采样的这样一个策略。固定对手此时的策略,然后不断的训练我方策略直至收敛,使该策略成为在别的玩家策略不变的情况下,近似的最优的一个响应,然后将其加入该玩家的策略池中,这样来维护策略池的多样性。我们就在不断的博弈训练中,既提高了逃跑者也提高了追逐者的水平,并通过对手策略多样性保证自己的策略是通用的,有更好的泛化性。

强化学习在大机动飞行中的应用#
基于视觉的窄缝穿越:网络输入图片,通过一个视觉的 encoder 编码器进行解析编码,最后直接输出控制指令(角速度和推力),一个难点是我们输入的图片是高维的,直接让网络同时去学习图片的感知理解与高精度运动控制是很难的,需要大量的数据,同时对解空间的探索效率是很低的。
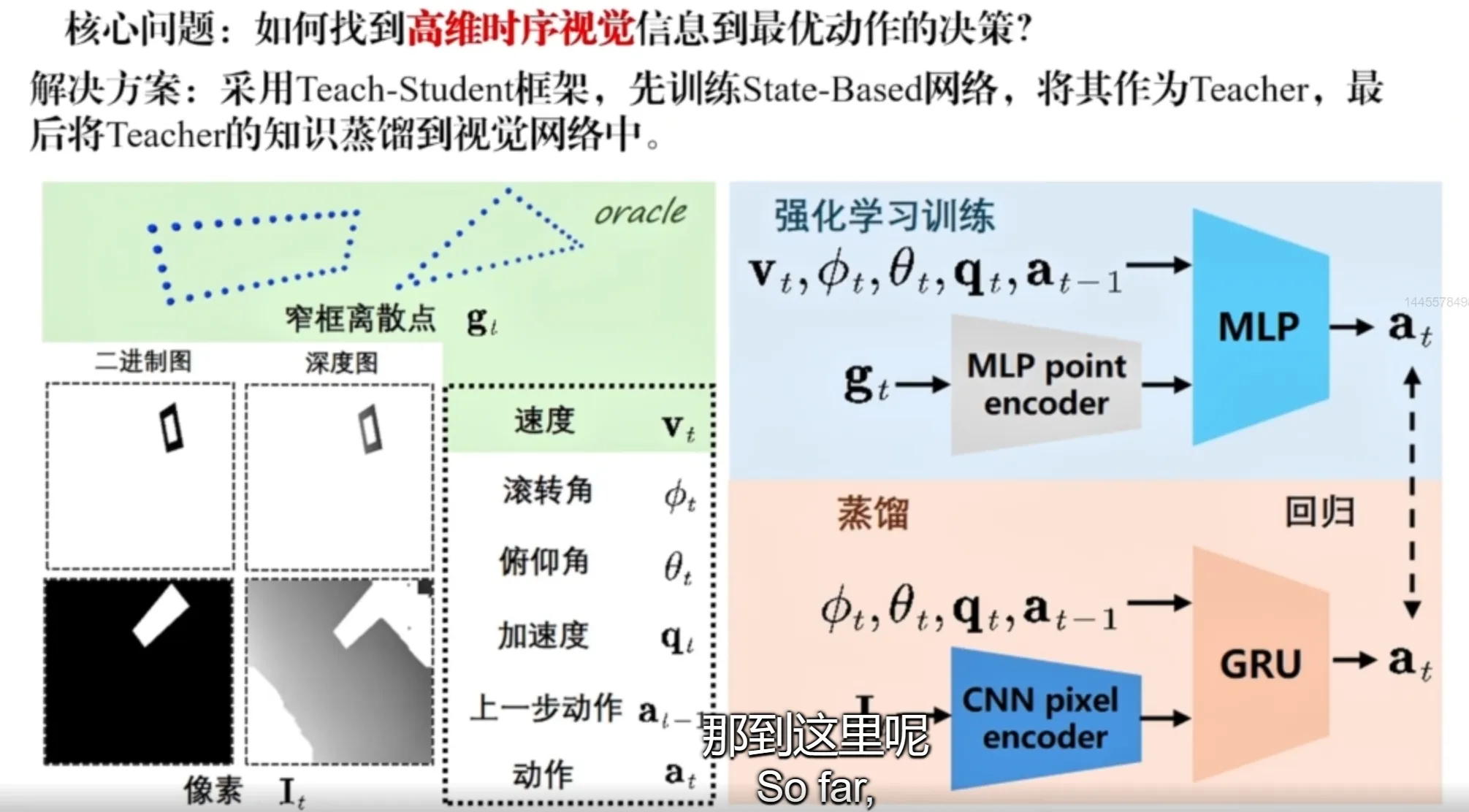
方法:用 teach-student 这个框架,把希望无人机穿越的框(窄缝)的角点提取出来,去训练一个 teacher,它只需要关注无人机的运动控制,然后通过在线蒸馏,去监督 teacher 的输出和 student 的输出,得到一个真正要使用的 student 网络。这种方法可以提供一个更加明确的进化方向,显著提升网络的学习效率。并在网络结构上使用 GRU(一个 RNN 的网络结构),使训练出的 policy 对感知数据是有记忆的(因为这个网络里需要隐式的做窄缝的估计和识别),得到的多帧信息要比单帧信息要好,也可凭借之前的记忆(之前的观测),去完成后续的动作。
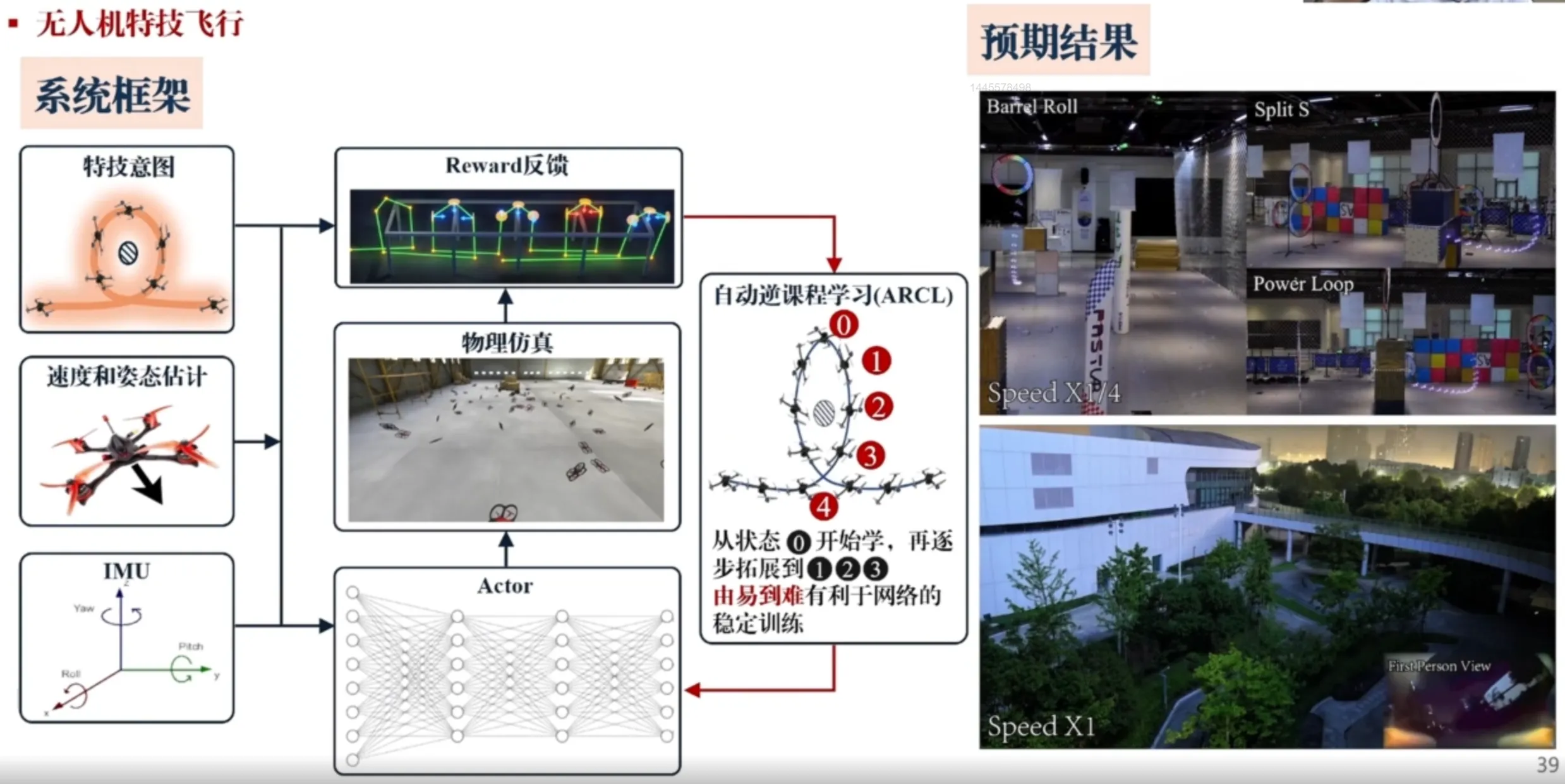
实现无人机特技飞行——自动逆课程学习(ARCL)